Основи інженерії штучного інтелекту 10-11 класи
| Сайт: | AI Lab |
| Курс: | 🤖 Матеріали курсу "Основи інженерії штучного інтелекту" |
| Книга: | Основи інженерії штучного інтелекту 10-11 класи |
| Надруковано: | Гість-користувач |
| Дата: | субота 12 липня 2025 12:58 PM |
Опис
Цей документ містить навчальні матеріали для учнів та вчителів курсу «Основи інженерії штучного інтелекту». Навчальна програма курсу за вибором "Основи інженерії штучного інтелекту" Автори: Рибак О.С., Радер Р.І. Протокол №7 від 19.08.2024. Зареєстровано у каталозі надання грифів навчальних матеріалів та навчальних програм № 4.0164-2024 (Текст програми (pdf))
Зміст
- 1. Вступ
- 2. Основи штучного інтелекту
- 3. Програмування для ШI
- 3.1. Основи та базовий синтаксис Python
- 3.2. Лабораторна робота: перші кроки з інтерпретатором Python
- 3.3. Списки та бібліотеки для машинного навчання
- 3.4. Словники та умовні оператори. Лабораторна робота.
- 3.5. Бібліотека Pandas. Робота із наборами даних. Практична робота із прогнозування якості повітря.
- 3.6. Задачі для самостійної роботи
- 4. Інструменти роботи в команді
- 5. Комп'ютерний зір
- 6. Практичне застосування ШІ
- 7. Математика для ШІ
- 8. Основи машинного навчання
- 9. Збір даних
- 10. Нейронні мережі
- 11. Основи обробки природної мови
- 12. Природна мова та генеративний ШІ
- 13. Глибинне навчання
- 14. Проєктна діяльність
1. Вступ
![]()
Сьогодні індустрія інформаційних технологій як ніколи потребує кваліфікованих інженерів, і це питання актуальне й для України. Технологічний розвиток є важливим кроком до нашого майбутнього, особливо в умовах війни. Українська освіта, як основа підготовки майбутніх професіоналів, відіграє ключову роль у збереженні конкурентоспроможності країни та забезпеченні подальшого зростання. Вона має адаптуватися до нових викликів, надаючи учням сучасні знання та навички для роботи у сфері високих технологій.
Вивчення програмування та інженерії через призму штучного інтелекту допомагає учням залишатися на передовій технологій. Цей документ створений, щоб зацікавити учнів та підготувати до життя в світі, де штучний інтелект проникає у всі сфери діяльності та змінює наші уявлення про технології та їх застосування.
Обґрунтування для вивчення штучного інтелекту в школі
Незнання природи штучного інтелекту
Люди все частіше взаємодіють із ШІ, свідомо чи ні. ШІ використовується для керування автомобілями, автоматизації обслуговування клієнтів, виявлення цілей для військових дій, скринінгу заявників на в'їзд у країни, управління поліцейськими діями, визначення оцінок, відбору кандидатів до університетів та навіть прийняття рішень щодо особистих фінансів [unesco2022k12ai] .
Незнання того, як він працює, може призводити до хибних уявлень про його можливості та обмеження. Вивчення технологій у школі є вкрай важливим, оскільки воно дозволяє учням краще розуміти, як вони впливає на їхнє повсякденне життя, від освіти до особистих фінансів. Це навчання забезпечує необхідні знання для критичного аналізу застосувань ШІ та потенційних ризиків.
Етичні аспекти штучного інтелекту
Використання штучного інтелекту пов'язане з багатьма етичними питаннями. Наприклад, у систему можуть потрапити упередження через дані, які використовуються для навчання, або через рішення розробників, що може призвести до дискримінації. Крім того, через складність деяких алгоритмів ШІ їхні рішення важко пояснити чи перевірити, що створює проблеми з прозорістю та зрозумілістю роботи таких систем.
Знання про етичні аспекти штучного інтелекту сприяють формуванню у молоді усвідомлення про можливі упередження та дискримінацію, що можуть виникати через використання ШІ. Це навчання дозволяє учням розуміти важливість прозорості рішень, прийнятих на основі ШІ, що є необхідним для розробки справедливих і етичних технологій.
Вплив ШІ на ринок праці
Штучний інтелект вже сьогодні значно змінює ринок праці, і ці зміни торкаються професій всіх рівнів освіти та зарплат. Вивчення ШІ в школах є необхідним для того, щоб учні могли адаптуватися до цих змін та краще розуміти вимоги майбутніх професій в умовах зростаючої автоматизації.
Пандемія COVID-19 лише прискорила темпи автоматизації, через що до 2030 року кожен шістнадцятий працівник може потребувати перекваліфікації, а кількість робочих місць середнього та низького рівня кваліфікації значно зменшиться.
Попит на спеціалістів з ШІ
Інженерні компанії все більше потребують фахівців зі штучного інтелекту. Раннє включення освіти з ШІ дозволяє учням розвивати необхідні навички та компетенції, які затребувані на ринку праці, що стає все більш залежним від провідних технологій.
Компанії продовжують робити значні технічні інвестиції у ШІ, і для цього потрібен новий набір навичок та здібностей. Близько 22% вакансій на технічні ролі в компанії Alphabet (материнська компанія Google) та 13% вакансій в Apple вимагають знання в таких областях, як машинне навчання та обробка природної мови. Таким чином, знання штучного інтелекту стають основоположними для майбутньої кар'єри в багатьох галузях [Bloomberg-2023-workshift, grammarly-restructuring, hrdrive-layoffs].
Огляд основних тем
Штучний інтелект — це парасольковий термін, який об’єднує різноманітні технології, спрямовані на створення систем, здатних виконувати завдання, що зазвичай вимагають людського інтелекту. До них належать машинне навчання, обробка природної мови, комп’ютерний зір, робототехніка, експертні системи та інші підходи. Кожна з цих технологій має свої унікальні методи та застосування, але всі вони спрямовані на автоматизацію аналізу даних, прийняття рішень або виконання складних операцій
Навчальна програма курсу за вибором "Основи інженерії штучного інтелекту" Автори: Рибак О.С., Радер Р.І. Протокол №7 від 19.08.2024. Зареєстровано у каталозі надання грифів навчальних матеріалів та навчальних програм № 4.0164-2024 (Текст програми (pdf)). Експертний висновок 1 (pdf), Експертний висновок 2 (pdf)
2. Основи штучного інтелекту
Штучний інтелект - це галузь інформатики, яка займається розробкою інтелектуальних систем, здатних виконувати завдання, які зазвичай потребують людського інтелекту. Завдяки цим технологіям ШІ знаходить застосування в найрізноманітніших сферах життя.
Корисні посилання:
Курс Microsoft по штучному інтелекту для початківців
2.1. Вступ до штучного iнтелекту
Історія розвиту ШІ сповнена досягнень, інновацій та складнощів.

Таймлайн з https://www.linkedin.com/pulse/rise-artificial-intelligence-why-matters-alexander-stahl/
Перша обчислювальна машина: Harvard Mark I
Harvard Mark I — одна з перших обчислювальних машин, яка зробила вагомий внесок у розвиток технологій, що пізніше стануть основою для ШІ. Ця машина була створена в середині 20-го століття і заклала фундамент для подальших розробок у сфері обчислень. Детальніше: Harvard Mark I на Wikipedia.
Тест Тюрінга (1950)
У 1950 році англійський учений Алан Тюрінг опублікував статтю "Обчислювальні машини та інтелект", у якій описав тест для визначення моменту, коли машина може зрівнятися з людиною за рівнем інтелекту. Ця процедура отримала назву "тест Тюрінга" та була натхненна вечірньою грою "Imitation Game" (імітаційна гра). У грі чоловік і жінка відповідали на серію письмових запитань, а завданням учасників було визначити, хто є ким. Тюрінг запропонував замінити одного з учасників машиною та поставити питання: "Чи буде той, хто питає, помилятися так само часто, як у випадку з людиною?". Таким чином, тест Тюрінга став важливим орієнтиром у розвитку ШІ. Детальніше: Тест Тюрінга на Wikipedia.
Logic Theorist (1956)
Програма Logic Theorist, створена Аланом Ньюеллом і Гербертом Саймоном у 1955 році, стала першою серйозною спробою моделювати людське мислення. Вона була представлена в рамках досліджень на конференції в Дартмутському коледжі — події, що офіційно започаткувала термін "штучний інтелект". Logic Theorist вирішувала логічні теореми за допомогою методів дедукції, формулюючи їх у вигляді символічних виразів. Ця програма могла не лише розв'язувати задачі, а й генерувати нові теореми, що стало важливим досягненням для ШІ. Детальніше: Logic Theorist на Wikipedia.
Злети та падіння: Зима штучного інтелекту
Штучний інтелект пережив кілька періодів спаду інтересу та фінансування, відомих як "AI Winter". Один із таких періодів розпочався у 1980-х роках, коли високі очікування від експертних систем — програм, які імітували знання експертів у певній галузі — не виправдалися через обмеженість обчислювальних ресурсів і складність підтримки. Детальніше: Експертні системи на Wikipedia.
У цей час також з'явився масштабний японський проєкт Fifth Generation Computer Systems, який мав на меті створення передових комп'ютерів "пʼятого покоління" на базі ШІ. Хоча проєкт зазнав невдачі, він привернув значну увагу до обчислювальних можливостей і викликів ШІ. Детальніше: Fifth Generation Computer Systems на Wikipedia.
Новітні досягнення у штучному інтелекті
В останні роки розвиток ШІ набрав вражаючих обертів завдяки зростанню обчислювальних потужностей та ефективності алгоритмів. Ідеї, сформульовані десятиліттями раніше, нарешті отримали змогу реалізувати свій потенціал.
Наприклад, у 2005 році автономний транспортний засіб Стенфордського університету, Stanley, виграв DARPA Grand Challenge, доводячи, що ШІ може успішно вирішувати завдання автономного водіння.
У 2014 році DeepMind продемонструвала прорив, коли їхні агенти почали грати в ігри на Atari 2600 на суперлюдському рівні, використовуючи глибоке підкріплене навчання. В 2016 році відбувся історичний матч AlphaGo - Лі Седоль, який завершився перемогою компʼютера із рахунком 4:1.
У 2019 році OpenAI випустила мовну модель GPT-2, яка показала величезні можливості генерації тексту, а в 2020 році Waymo запустила повністю автономну таксомоторну службу, надаючи послуги широкому загалу.
У 2022 році OpenAI презентувала ChatGPT, що підняло рівень розмовного ШІ на нові висоти, а в 2023 році Meta і OpenAI продовжили викликати дискусії про майбутнє розробки ШІ через витік моделей і нові можливості налаштування систем.
Ці досягнення підтверджують, що ШІ продовжує швидко розвиватися, стаючи все більш важливим інструментом для розв'язання складних проблем і створення інновацій.

2.2. Моральна машина та проблема вагонетки. Лабораторна робота.

Проблема вагонетки – це класичний етичний експеримент, у якому людина повинна обрати між тим, щоб залишити вагонетку на її поточному шляху (де вона зіб’є п’ятьох людей), або перевести її на інший шлях, де постраждає одна людина.

Сенс експерименту у тому, щоб змусити задуматися над моральними дилемами: що важливіше – кількість врятованих життів, їхня цінність чи дія/бездіяльність, яка до цього призвела. Це особливо актуально для розробки алгоритмів у сфері штучного інтелекту, які мають ухвалювати подібні рішення.
Лабораторна робота: Дослідження етичних аспектів ШІ за допомогою "Моральної машини"
Мета: Ознайомитися з етичними дилемами, які виникають при розробці автономних систем, і дослідити, як люди приймають рішення в ситуаціях морального вибору.
Moral Machine — це онлайн-платформа, розроблена дослідниками MIT у 2016 році для вивчення етичних рішень, які автономні транспортні засоби можуть приймати в критичних ситуаціях. Платформа пропонує серію моральних дилем, де авто має вибирати, наприклад, між жертвуванням пішоходами чи пасажирами, молодими чи старими людьми, або навіть між людьми й тваринами. Метою проекту було зібрати дані про те, як люди з різних культур реагують на такі ситуації, щоб допомогти сформувати етичні рамки для розвитку штучного інтелекту в автономних системах.
- Відкрити сайт https://moralmachine.net/
- Натиснути кнопку Start judging
- Приймати рішення у кожному сценарії, аргументуючи свої дії
Після завершення експерименту, провести обговорення на тему того які моральні принципи були використані при прийнятті рішень, та як ці рішення можуть бути інтегровані в алгоритми ШІ?
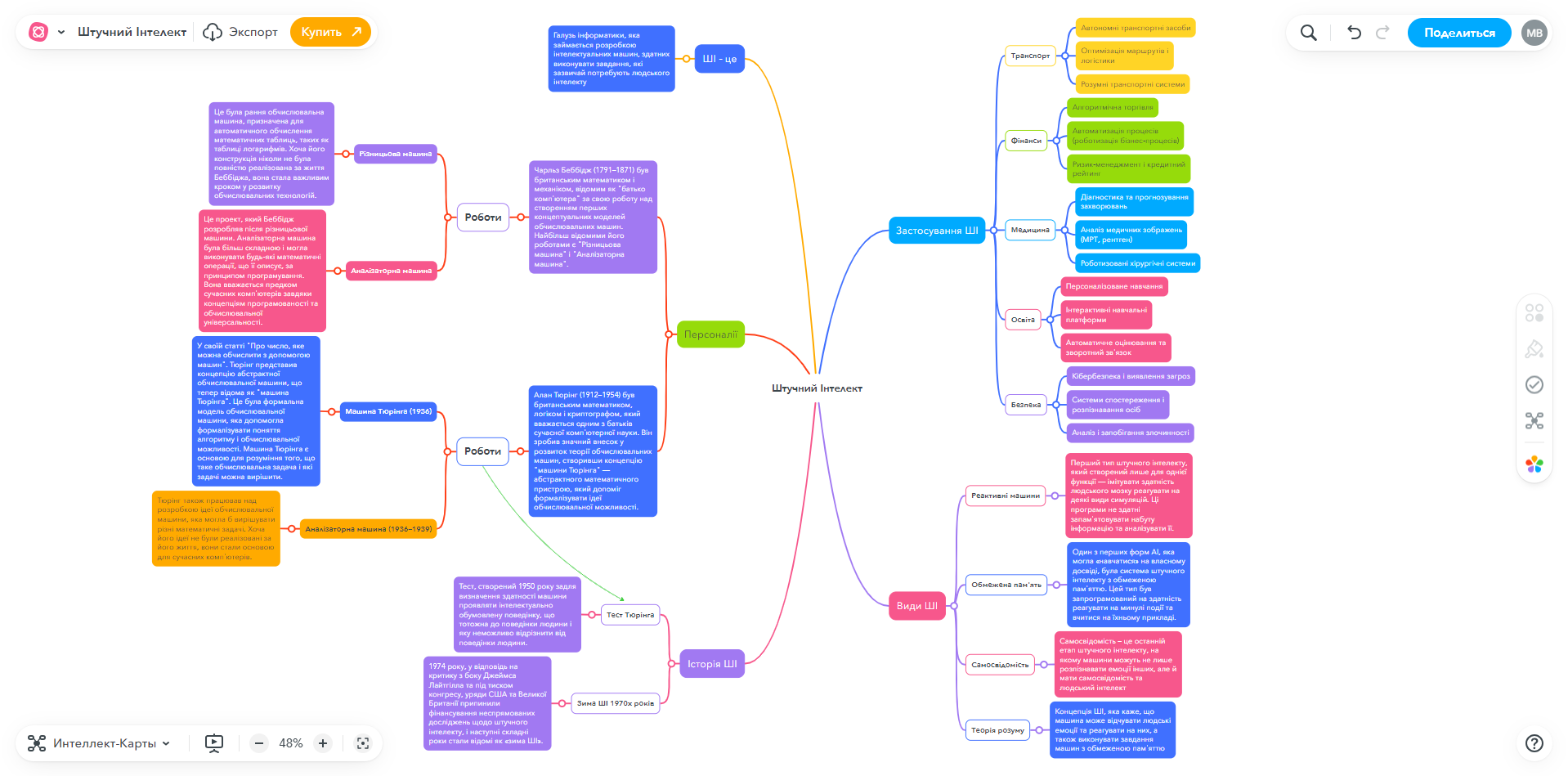
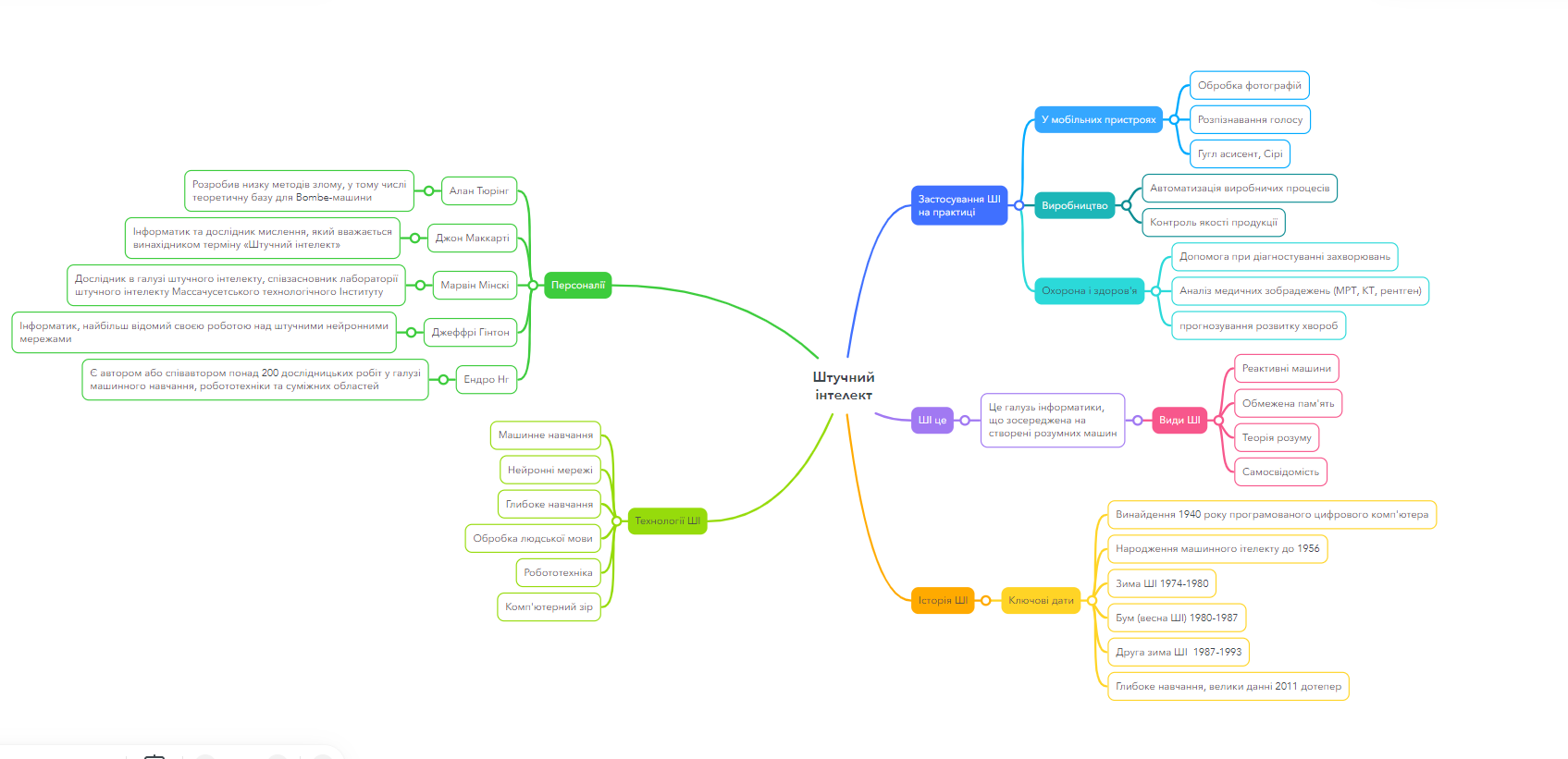
2.3. Практична робота: Створюємо мапу думок про історію ШІ
Мета: Узагальнити та структурувати знання з історії, технологій та ключових термінів у сфері штучного інтелекту. Навчитись будувати мапи думок для візуалізації звʼязків.
Завдання:
- Реєструємось на https://www.mindmeister.com/ (або аналогічному сервісі для побудови мап думок - mind maps)
- Створюємо мапу думок з центральною темою: "Штучний інтелект".
- Додаємо 5 основних гілок:
- Оформлюємо мапу: додаємо всі підпункти у гілки, звʼязуємо елементи між гілками
Оцінювання:
- Чіткість структури
- Повнота
- Зовнішній вигляд
Приклади робіт:
1.
2.
2.4. Чи може машина думати? “Тест Тюрінга”
Після завершення Другої світової війни Алан Тюрінг, відомий своїми досягненнями в криптоаналізі, продовжив дослідження в галузі обчислювальної техніки. Він зацікавився питанням: як можна визначити момент, коли комп’ютери стануть настільки розумними, що зможуть зрівнятися з людиною у здатності мислити?
У своїй статті «Обчислювальні машини та інтелект», опублікованій у 1950 році, Тюрінг запропонував такий підхід: замість того, щоб ставити абстрактне запитання «Чи може машина думати?», він створив практичний тест, заснований на імітації людської поведінки. Процедура згодом була названа «тестом Тюрінга» та ґрунтувалася на грі «Імітація», де учасники намагаються вгадати з ким вони спілкуються, з чоловіком чи з жінкою, використовуючи запитання на записках.


Тюрінг запропонував, щоб у цій грі роль одного з учасників виконувала машина. Завдання іншого учасника полягало в тому, щоб визначити, чи є співрозмовник людиною, чи машиною. Якщо машина здатна успішно імітувати людину настільки, що суддя не може відрізнити її від реальної людини, це означає, що вона досягла певного рівня інтелекту. Тест Тюрінга став ключовою концепцією у визначенні інтелекту машин, та використовується і сьогодні.
Проведення експерименту "Гра в імітацію" класі

- Розділення на команди
- Розділити клас на три команди: Інженери, Люди та Експерти
- Кожній команді дається коротка інструкція щодо їхньої ролі та завдань.
- Підготовка до гри в імітацію
- Інженери: Спілкуються із ChatGPT (виконують інженерію запитів, prompt engineering) для налаштування персонажа, від імені якого компʼютер буде відповідати на запитання. Намагаються навчити його відповідати так, як відповіла би справжня людина.
- Люди: Обирають персонажа, якого будуть імітувати, і готуються відповідати на запитання від експертів.
- Експерти: Формулюють 10 різноманітних запитань, спрямованих на виявлення відповідей компʼютера.
- Проведення гри
- Усі команди вводять свої відповіді в Google Forms.
- Вчителю потрібно забезпечити, щоб усі відповіді були анонімними. Для цього експерти мають бути ізольованими (у різних кінцях класу) від команд людей та інженерів.
- Аналіз відповідей та обговорення
- Експерти оцінюють відповіді та намагаються визначити, хто є машиною, а хто людиною.
2.5. Карʼєра у сфері ШІ
Огляд сфер, де застосовується ШІ із використанням карʼєрних карток: https://ai4ga.org/careers/


Завдання: Розглянути карʼєрні картки, перекласти їх вміст та розібратись із задачами кожної із представлених професій.
Завдання: Знайдіть сервіс із ШІ який ви ще не бачили зі списку https://www.aixploria.com/en/ultimate-list-ai/
2.6. Питання для самоперевірки
Як називався перший програмований комп'ютер?
- DARPA
- Mark 1
- Enigma
- Turing
Яка мета Тесту Тюрінга, запропонованого Аланом Тюрінгом у 1950 році?
- Перевірити здатність комп'ютера обчислювати математичні задачі
- Оцінити швидкість роботи комп'ютера
- Перевірити якість аудіо на комп'ютері
- Визначити, чи може комп'ютер мислити як людина
Що означає термін "AI Winter"?
- Час, коли нейронні мережі вперше перемогли у шахи
- Період, коли інтерес до штучного інтелекту різко зріс
- Період застою у розвитку штучного інтелекту через невиправдані очікування
- Період активного розвитку експертних систем
Яка основна роль експертних систем у штучному інтелекті?
- Виконувати звичайні офісні завдання
- Створювати комп'ютерні ігри
- Використовувати знання експертів для прийняття рішень у вузькоспеціалізованих галузях
- Відтворювати людське мислення в простих завданнях
В чому особливість комп’ютерів п'ятого покоління, які розробляли в Японії в 1980-х?
- Комп'ютери, які були створені для обчислення квантових задач
- Комп'ютери, які створені для виконання логічних висновків та машинного навчання
- Комп'ютери, які використовують традиційні транзистори
- Комп'ютери, спеціально розроблені для графічного дизайну
Яке досягнення у грі Ґо стало важливою віхою для нейронних мереж та штучного інтелекту?
- Комп'ютер Deep Blue переміг у грі Ґо
- Нейронна мережа AlphaGo перемогла чемпіона світу з Ґо у 2016 році
- Комп'ютер навчився грати у Ґо за допомогою експертних систем
- Перша комп'ютерна програма зіграла партію у Ґо
Чому проблема вагонетки важлива для розробників штучного інтелекту?
- Вона допомагає визначити найшвидший шлях вирішення проблем
- Вона допомагає удосконалити швидкість обчислень
- Вона вчить, як створювати штучний інтелект для управління транспортом
- Вона демонструє, як моральні дилеми можуть бути важкими для програмування автономних систем
Хто такий Data Scientist, як роль в IT сфері?
- Спеціаліст із забезпечення кібербезпеки
- Спеціаліст, який розробляє апаратне забезпечення для ШІ
- Інженер, який програмує комп'ютерні ігри
- Людина, яка аналізує дані та розробляє алгоритми для машинного навчання
Яка роль Machine Learning Engineer у команді, що займається розробкою штучного інтелекту?
- Писати технічну документацію для програмного забезпечення
- Розробляти алгоритми машинного навчання
- Створювати графічні інтерфейси користувача
- Адмініструвати комп'ютерні мережі компанії
Чим займається AI Research Scientist?
- Проводить дослідження в галузі нових алгоритмів і технологій штучного інтелекту
- Керує командами розробників
- Налаштовує апаратне забезпечення для запуску програм
- Тестує програмне забезпечення
Заповніть пропуски у тексті:
Одного ранку в 2070 році учень Олексій прокинувся завдяки смарт-годиннику, який використав ________ для аналізу його циклів сну і розбудив у найкращий час. Під час сніданку він попросив голосового помічника, що вміє робити розпізнавання ________, включити музику.
У школі Олексій на уроках вчитель математики згадав першу програму, що могла вирішувати математичні теореми, відому як ________, створену у 1956 році. Вона вважається першою програмою штучного інтелекту, яка може робити логічні висновки.
Після уроку математики Олексій зайшов на урок інформатики, де його запросили взяти участь у проєкті зі створення моделі машинного навчання. Учень дізнався, що для цього в Японії розробляли спеціальні комп'ютери ________ покоління, які мали підтримувати обробку природної мови та паралельні обчислення.
Після школи Олексій вирішив відпочити, зігравши партію в гру Go на своєму смартфоні. Він пригадав, як у 2016 році програма _______, що базується на нейронних мережах, перемогла чемпіона світу Лі Седоля.
Перед сном, Олексій подумав про те, що самокеровані автомобілі, що використовують технологію ________ навчання, ще не були звичайним явищем на дорогах ще 40 років тому. Але як вони будуть вирішувати моральні дилеми, якщо постане такий вибір? Так, проблема ________ все ще залишалась невирішеною, навіть у 2070 році.
3. Програмування для ШI
Інженерія штучного інтелекту охоплює процеси, що включають розробку, впровадження та оптимізацію AI-систем для вирішення практичних задач у різних галузях. Основна мета інженерії штучного інтелекту полягає в створенні алгоритмів і моделей, здатних автоматизувати виконання завдань, аналізувати великі обсяги даних та приймати рішення.
Python – Мова програмування для штучного інтелекту
Python є однією з найпопулярніших мов програмування, що активно використовується для розробки рішень у галузі штучного інтелекту (ШІ) та машинного навчання (ML). Її переваги включають:
- Легкість у навчанні та читанні коду.
- Велику кількість бібліотек для ШІ.
- Кросплатформеність.
Приклади застосування Python у машинному навчанні:
- Аналіз настроїв (sentiment analysis): створення моделі для обробки тексту та визначення позитивного чи негативного настрою, наприклад, за допомогою бібліотеки
NLTK. - Класифікація зображень: використання бібліотек, як-от
TensorFlowчиPyTorch, для побудови згорткових нейронних мереж, що визначають категорію зображення. - Прогноз погоди: тренування моделі на основі часових рядів (time-series) за допомогою бібліотеки
scikit-learn, що аналізує історичні дані для передбачення погоди. - Комп'ютерний зір: програмування розпізнавання та виділення об'єктів на зображеннях за допомогою бібліотеки
OpenCV.
3.1. Основи та базовий синтаксис Python
"Межі моєї мови визначають межі мого мислення"
Людвіг Вітгенштайн
Що таке Python?
Гвідо ван Россум

Python — це високорівнева мова програмування, створена у 1991 році Гвідо ван Россумом. Вона розроблена для того, щоб зробити програмування доступним і зрозумілим для новачків. Наприклад, найпростіша програма на Python виглядає так:
print("Hello, World!")
Відступи
У Python відступи використовуються для позначення блоків коду. Це можуть бути пробіли або табуляція. Наприклад:
if 5 > 2: print("5 більше ніж 2")
Коментарі
Коментарі допомагають пояснити код для себе або інших розробників. У Python коментарі починаються зі знака # і ігноруються під час виконання програми. Наприклад:
# Це коментар# Наступний рядок виконається
print(15 + 10) # Частина справа від # — це коментар
Імена змінних
Імена змінних у Python зазвичай пишуться у стилі snake_case, де слова розділяються нижнім підкресленням.
Змінні, типи даних, умовні оператори
Змінні використовуються для зберігання даних. Python підтримує різні типи даних, наприклад, числа, рядки, списки тощо. Ось приклад:
age = 18if age >= 18: print("Дорослий")else: print("Неповнолітній")
Цикли
Цикли використовуються для повторення дій. У Python є два основних типи циклів: for і while.
Цикл for:
for i in range(5): print(i) # Виведе числа від 0 до 4
while:count = 0while count < 5: print(count) count += 1
Бібліотеки
Python має багато вбудованих і зовнішніх бібліотек для різних задач. Вбудовані бібліотеки можна використовувати в будь-якій програмі, а зовнішні перед використанням потрібно встановити на ваш компʼютер.
Вбудована бібліотека os використовується для роботи із файлами на компʼютері, а random - для генерації випадкових чисел:
import randomprint(random.random())
Для роботи з машинним навчанням ми будемо використовувати зовнішню бібліотеку sklearn:
from sklearn.linear_model import LogisticRegression
Python як калькулятор
Python дозволяє виконувати математичні операції без додаткових конструкцій. Наприклад:
5 + 3 # Додавання
10 - 2 # Віднімання
4 * 7 # Множення
2 ** 3 # Піднесення до степеня
Ділення у Python
У Python існує три оператори ділення:
/— звичайне ділення, яке повертає число з плаваючою комою:7 / 2 # Результат: 3.5//— цілочисельне ділення:7 // 2 # Результат: 3%— залишок від ділення:7 % 2 # Результат: 1
Створення змінних
Змінні дозволяють зберігати дані для подальшого використання:
x = 10y = 25
print(x + y) # Результат: 35
Виведення на екран за допомогою print
Рядки у Python — це послідовності символів. Їх можна оголошувати за допомогою одинарних або подвійних лапок:
'Це рядок'"І це теж рядок"
Приклад використання змінних і виведення:
greeting = "Привіт, світ!"print(greeting)
Функція print дозволяє виводити текст разом із змінними:
name = "Roman"age = 30print("Мене звати", name, "і мені", age, "років.")
Об'єднання рядків:
first_name = "Roman"last_name = "Illiych"full_name = first_name + " " + last_nameprint("Повне ім'я:", full_name)
Рядки також мають спеціальні методи:
- Змінити всі літери на великі:
print(greeting.upper()) - Змінити всі літери на малі:
print(greeting.lower()) - Порахувати кількість входжень символу:
print(greeting.count('в')) - Замінити частину рядка:
print(greeting.replace("світ", "Python"))
3.2. Лабораторна робота: перші кроки з інтерпретатором Python
Завдання №1: Розрахунок формул
Ви працюєте над програмою для розрахунку площі та об'єму циліндра. Використайте наступні формули:
- Площа основи циліндра: \( A = \pi r^2 \) , де A — площа основи, r — радіус основи циліндра, а \( \pi \) — константа (3.14159).
- Об'єм циліндра: \( V = A \times h \) , де V — об'єм циліндра, A — площа основи, а h — висота циліндра.
Завдання:
- Створіть змінні для радіуса
rта висотиh. - Використайте значення
pi = 3.14159. - Обчисліть площу основи
A. - Обчисліть об'єм циліндра
V. - Виведіть на екран результати розрахунків з точністю до 2 знаків після коми.
При радіусі r = 5 і висоті h = 10, ваш код повинен вивести:
- Площа основи: 78.54
- Об'єм циліндра: 785.40
# Почніть вашу програму із створення змінних:r = ...h = ...pi = ...
Завдання №2: Робота з текстом для обробки природної мови (NLP)
Ви починаєте знайомитися з машинним навчанням. Ваше завдання — навчитися працювати з рядками (текстовими даними), що є основою для багатьох завдань в NLP (natural language processing, сфера машинного навчання пов'язана із обробкою природної мови), таких як аналіз тексту або робота з повідомленнями від користувачів.
Задана текстова фраза:
"Привіт! Я вивчаю машинне навчання і Python."Виконайте наступні дії:
- Крок 1: Вивести довжину цієї фрази за допомогою функції
len(). - Крок 2: Перевести фразу в нижній регістр за допомогою функції
lower(). - Крок 3: Перевести фразу у верхній регістр за допомогою функції
upper(). - Крок 4: Порахувати, скільки разів у тексті зустрічається слово
"машинне"за допомогоюcount(). - Крок 5: Замінити слово
"Python"на"NLP"за допомогоюreplace().
- Крок 1: Вивести довжину цієї фрази за допомогою функції
Результати, які має отримати програма:
- Довжина фрази: 43 символи.
- Фраза у нижньому регістрі:
"привіт! я вивчаю машинне навчання і python." - Фраза у верхньому регістрі:
"ПРИВІТ! Я ВИВЧАЮ МАШИННЕ НАВЧАННЯ І PYTHON." - Слово
"машинне"зустрічається: 1 раз. - Нова фраза після заміни:
"Привіт! Я вивчаю машинне навчання і NLP."
Додаткове завдання:
Вивести перші 5 символів і останні 5 символів цієї фрази окремо.
Завдання 3 (*): Робота з текстом для обробки природної мови (NLP)
Задана текстова фраза:
"Машинне навчання — це підгалузь штучного інтелекту, що надає комп'ютерам здатність до навчання без явного програмування логіки."Виконайте наступні дії:
Крок 1: Виведіть кількість слів у фразі.
(Підказка: використовуйте методsplit()для поділу тексту на слова.)Крок 2: Підрахуйте, скільки разів зустрічається слово
"навчання".Крок 3: Видаліть усі коми з тексту.
(Використовуйте методreplace().)Крок 4: Розбийте текст на окремі речення.
(Підказка: використовуйте методsplit('.').)Крок 5: Перетворіть текст у список слів і видаліть стоп-слова.
Список стоп-слів:"це","що","і","без".
Додаткове завдання:
Після виконання попередніх кроків, з'єднайте отримані слова назад в один рядок через пробіл і виведіть новий текст.
3.3. Списки та бібліотеки для машинного навчання
Списки в Python
Списки є однією з основних структур даних у Python. Вони дозволяють зберігати кілька значень в одному об'єкті, що робить їх надзвичайно корисними в задачах обробки даних та машинного навчання.
Основні властивості списків:
- Списки можна змінювати: додавати, видаляти або змінювати елементи.
- Можуть містити елементи різних типів (наприклад, рядки, числа тощо).
- Підтримують різноманітні операції, такі як обчислення суми, пошук максимального та мінімального значення.
Приклад створення списку:
my_list = [1, 2, 3, 4, 5]# Доступ до елементів за індексомprint(my_list[0]) # Перший елементprint(my_list[2]) # Третій елементprint(my_list[-1]) # Останній елемент# Зріз списку (отримання частини списку)print(my_list[0:3]) # Елементи з 0 до 2 включно# Додавання нового елементаmy_list.append(60)# Об'єднання списківprint(['яблуко'] + ['ананас', 'апельсин'])# Пошук максимального, мінімального значення та довжини спискуprint('Найбільший елемент:', max(my_list))print('Найменший елемент:', min(my_list))print('Кількість елементів:', len(my_list))
Бібліотеки для машинного навчання
NumPy - бібліотека для швидких обчислень
NumPy — це популярна бібліотека Python для роботи з масивами чисел. Вона широко використовується в задачах числових обчислень та машинного навчання.
Особливості NumPy:
- Створення та робота з багатовимірними масивами.
- Швидке виконання математичних операцій.
- Функції для лінійної алгебри, статистики та генерації випадкових чисел.
Приклад використання NumPy:
import numpy as np# Створення масивуmy_array = np.array([1, 2, 3, 4, 5])# Обчислення середнього значенняprint(np.mean(my_array))# Пошук мінімального та максимального значенняprint(np.min(my_array))print(np.max(my_array))# Сума всіх елементів масивуprint(np.sum(my_array))# Фільтрація масиву за умовоюprint(my_array[my_array <= 20])
Бібліотека scikit-learn
scikit-learn — одна з найпопулярніших бібліотек для машинного навчання. Вона дозволяє створювати, навчати та оцінювати моделі.
Можливості scikit-learn:
- Готові алгоритми, такі як лінійна регресія, дерево рішень, метод найближчих сусідів тощо.
- Інструменти для попередньої обробки даних.
- Методи для оцінювання моделей та налаштування їх параметрів.
Приклад використання scikit-learn для лінійної регресії:
from sklearn.linear_model import LinearRegressionimport numpy as np# ДаніX = np.array([[1], [2], [3]])y = np.array([2, 4, 6])# Створення моделіmodel = LinearRegression()model.fit(X, y)# Прогнозуванняprint(model.predict([[4]])) # Прогноз для значення 4
Ця бібліотека є основою для багатьох завдань машинного навчання.
3.4. Словники та умовні оператори. Лабораторна робота.
Словники
Словник (dictionary) — це структура даних у Python, яка дозволяє зберігати дані у вигляді пар "ключ-значення". Словники дуже зручні, коли потрібно швидко знайти значення за певним унікальним ключем.
Основні властивості словників:
- Ключі повинні бути унікальними.
- Ключами можуть бути лише незмінні типи даних (рядки, числа, кортежі).
- Значення можуть бути будь-якими типами даних (списками, рядками, іншими словниками тощо).
- Словники є змінюваними (mutable), тобто їх можна змінювати після створення.
Словник можна створити кількома способами. Один із найпоширеніших способів — використання фігурних дужок {} з парою "ключ:значення" всередині.
Приклад створення порожнього словника:
my_dict = {}
Приклад створення словника з даними:
student_grades = { 'Alice': 95, 'Bob': 85, 'Charlie': 78}
Тут ключами є імена студентів (рядки), а значеннями — їхні оцінки (цілі числа).
Операції зі словниками
Доступ до значення за ключем
# Щоб отримати значення за ключем, використовуйте квадратні дужки [].print(student_grades['Alice']) # Виведе: 95
Додавання та оновлення значень
# Щоб додати нову пару "ключ-значення" або оновити існуюче значення, # достатньо присвоїти нове значення ключу.student_grades['David'] = 90 # Додаємо нового студентаstudent_grades['Alice'] = 98 # Оновлюємо оцінку Аліси
student_grades = {'Alice': 98, 'Bob': 85, 'Charlie': 78, 'David': 90}
Видалення елемента зі словника
# Використовуйте оператор del, щоб видалити елемент зі словника за ключем.del student_grades['David'] # Видаляє David з словника
student_grades = {'Alice': 98, 'Bob': 85, 'Charlie': 78}
Умовні оператори
Умови в Python використовуються для прийняття рішень в залежності від виконання певних умов. Основна конструкція для цього — це операторif. Він дозволяє перевірити логічний вираз, і якщо він істинний (True), виконується блок коду, що йде після нього. Для перевірки кількох умов можна використовувати elif, а для виконання дій, коли жодна з умов не виконана, використовується else. Логічні оператори, такі як and, or, not, дозволяють комбінувати умови для складніших перевірок. Наприклад:age = 18if age >= 18: print("Дорослий")else: print("Неповнолітній")
Повний оператор if може містити також оператор elif:
x = 10if x > 5: print("x більше 5")elif x == 5: print("x дорівнює 5")else: print("x менше 5")
Перевірка наявності ключа у словнику
# Щоб перевірити, чи є певний ключ у словнику, можна використовувати оператор in.if 'Alice' in student_grades: print("Оцінка Аліси:", student_grades['Alice']) if 'David' in student_grades: print("Оцінка Девіда:", student_grades['David'])
Оцінка Аліси: 98
Лабораторна робота: Робота із словниками
Завдання 1: Створення словника
Створіть словник students_grades, який зберігає інформацію про студентів та їхні оцінки з математики. Словник має містити наступні дані:
| Студент | Оцінка |
|---|---|
| Оля | 92 |
| Петро | 85 |
| Іван | 88 |
| Марія | 95 |
Ключами будуть імена студентів, а значеннями — їхні оцінки.
students_grades =
Виведіть оцінку Марії на екран.
Підказка: Згадайте синтаксис словників. Фігурні дужки використовуються щоб створити словник, а квадратні - щоб отримати значення по ключу. Використайте функцію print для виводу на екран.
Завдання 2: Додавання та оновлення даних у словнику
Додайте до словника ще одну студентку з ім'ям Анна та оцінкою 90.
Оновіть оцінку Петра на 89.
Виведіть словник після змін.
Завдання 3: Видалення елементів зі словника
Видаліть студента Івана зі словника.
Виведіть оновлений словник на екран.
Підказка: Використайте оператор del для видалення ключа із словника.
Завдання 4: Перевірка наявності ключа
Перевірте, чи є у словнику студентка з ім'ям Оля. Якщо так, виведіть її оцінку.
Якщо Ольги не знайдено, виведіть напис "Оцінка не знайдена".
Підказка: Використайте оператор if для перевірки, а else для виведення напису якщо умова не виконується.
Завдання 5: Підрахунок середньої оцінки
Використайте бібліотеку numpy для підрахунку середньої оцінки: створіть масив (np.array) з всіх оцінок, а потім викличте метод np.mean для підрахунку середньої оцінки.
Підказка: Всі значення словника (оцінки) у вигляді списку можна отримати за допомогою students_grades.values(), а перетворити їх на масив numpy можна так: np.array(students_grades.values())
3.5. Бібліотека Pandas. Робота із наборами даних. Практична робота із прогнозування якості повітря.
Забруднення повітря є однією з найбільших екологічних проблем сучасності, що впливає як на здоров’я, так і на довкілля. Особливо небезпечними є дрібнодисперсні частинки PM2.5 (частинки до 2.5 мікронів), які можуть проникати в легені й викликати серйозні захворювання дихальної та серцево-судинної систем. У Києві рівень PM2.5 часто зростає через смог, торфяні пожежі, а також вплив глобальних явищ, таких як пилові бурі з Сахари.
У цій практичній роботі ми проведемо аналіз якості повітря у м. Києві, використовуючи дані SaveEcoBot з станції №16788, розташованої у Дніпровському районі. Особливу увагу приділимо рівню PM2.5 за квітень 2024 року, коли на рівень забруднення могли вплинути як місцеві фактори, так і пилові бурі, зафіксовані метеорологами в інших регіонах України.
Мета: створити прогнозну модель для визначення рівня PM2.5, враховуючи історичні дані. Для цього ми використаємо інструменти машинного навчання, познайомимось із поняттям лінійної регресії та базовим методам аналізу часових рядів.
Набір даних з яким ми будемо працювати ви можете знайти за адресою https://www.kaggle.com/competitions/kyiv-air-quality-ai-lab-1 , або завантажити CSV файл напряму із сайту SaveEcoBot тієї станції яка знаходиться бліжче до вас (натисніть на посилання "Завантажити дані у форматі CSV").
У цій практичній роботі ми будемо використовувати бібліотеку Pandas для зручного читання, обробки та аналізу табличних даних. Вона допоможе нам очистити дані, виконати попередній аналіз і підготувати їх для побудови прогнозної моделі. Щоб працювати з Pandas, спочатку необхідно імпортувати її у свій проєкт, використовуючи команду import pandas as pd. Після чого можна використати функцію read_csv щоб прочитати таблицю із вимірюваннями:
import numpy as npimport pandas as pddf = pd.read_csv("/kaggle/input/kyiv-air-quality-ai-lab-1/saveecobot_16788 2.csv")

Візьмемо лише стовпчик pm25 та побудуємо його графік, щоб краще зрозуміти наші дані:
pm25_data = df[df["phenomenon"] == "pm25"]pm25_data = pm25_data.reset_index()pm25_data["value"].plot()
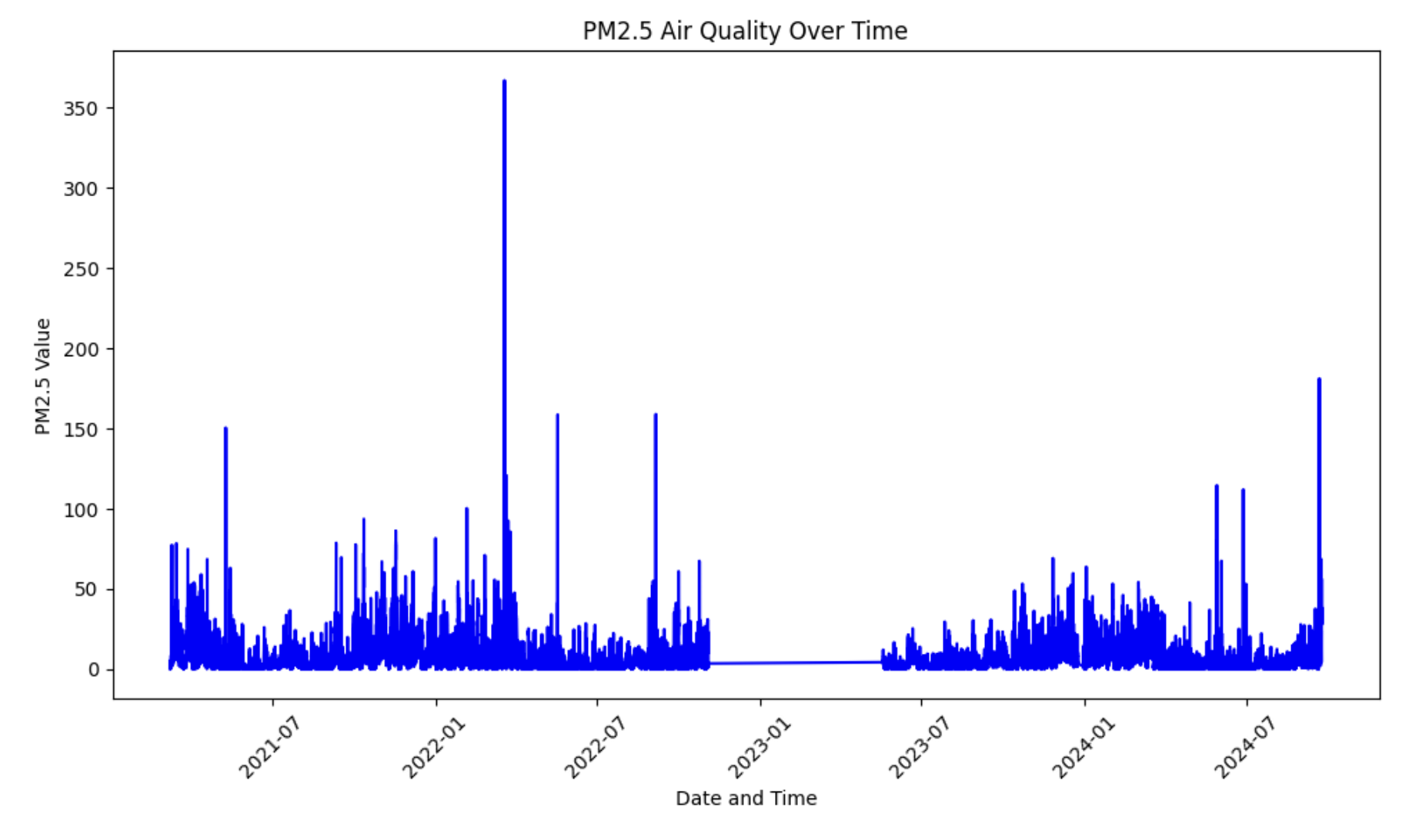
Тепер підготуємо дані для тренування прогнозної моделі. Для цього, спочатку треба розібратись що таке регресія.
| Регресія - це спосіб навчити комп’ютер передбачати числа. Наприклад, якщо ми знаємо, яка температура була вчора і позавчора, регресія допоможе передбачити, яка температура буде завтра. Вона шукає закономірність у даних і будує формулу, яка пов’язує одне з іншим. |
|---|
Більш формально, регресія - метод у машинному навчанні та статистиці, який використовується для виявлення залежності між змінними та прогнозування числового значення на основі цих залежностей.
Лінійна регресія — це найпростіший вид регресії, який шукає пряму лінію, що найкраще описує залежність між двома величинами.

Наприклад, для прогнозування температури повітря у найпростішому випадку змінна X може представляти температуру "сьогодні", а Y — температуру "завтра". Однак для більш якісного прогнозу зазвичай потрібно враховувати додаткові дані, такі як температура за "вчора", "позавчора", а також сезон чи місяць, у якому відбувається прогнозування. Ці додаткові фактори допомагають моделі краще зрозуміти закономірності та зробити точніше передбачення. Відповідно, змінна X насправді може бути не числом, а вектором, кожне число якого містить температуру за сьогодні та вчора, а також додаткові фактори як місяць та сезон. Наприклад: (-5, -4, 12, 4) може означати температуру -5 та -4 за два дні, 12 місяць (грудень), 4 сезон (зима).
Повернемось до якості повітря. Y у нас це якість повітря на завтра, а даними (X) будуть:
- якість повітря pm25 за вчора
- сьогоднішня дата
- номер місяця
- день тижня
from datetime import timedeltapm25_data['time_numeric'] = pm25_data['logged_at'].map(pd.Timestamp.toordinal)pm25_data['month'] = pm25_data['logged_at'].dt.monthpm25_data['weekday'] = pm25_data['logged_at'].dt.weekdaypm25_data['one_day_back'] = pm25_data['value'].shift(1)pm25_data.dropna(subset=['one_day_back'], inplace=True)# Define features and targetX = pm25_data[['month', 'one_day_back']]y = pm25_data['value']from sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)model = LinearRegression()model.fit(X_train, y_train)
Виконаємо кілька приготувань для того щоб зробити прогноз на наступні кілька днів. Створимо таблицю (DataFrame) future_data, яка буде містити X для всіх наступних 90 днів: дата, місяць, день тижня.
last_date = pm25_data['logged_at'].max()future_dates = [last_date + timedelta(days=i) for i in range(1, 90)]future_data = pd.DataFrame({ 'month': [date.month for date in future_dates], 'weekday': [date.weekday() for date in future_dates], 'one_day_back': np.nan})
last_pm25_value = pm25_data['value'].iloc[-1]for i in range(len(future_data)): future_data.loc[i, 'one_day_back'] = last_pm25_value last_pm25_value = model.predict(future_data.iloc[[i]][['month', 'one_day_back']])[0]predictions = future_data['one_day_back'].values
І намалюємо графік історичних даних та отриманих прогнозів одночасно:
plt.plot(pm25_data['logged_at'], pm25_data['value'], label='Historical PM2.5', marker='o')
plt.plot(future_dates, predictions, label='Predicted PM2.5', linestyle='--', color='red')
plt.show()
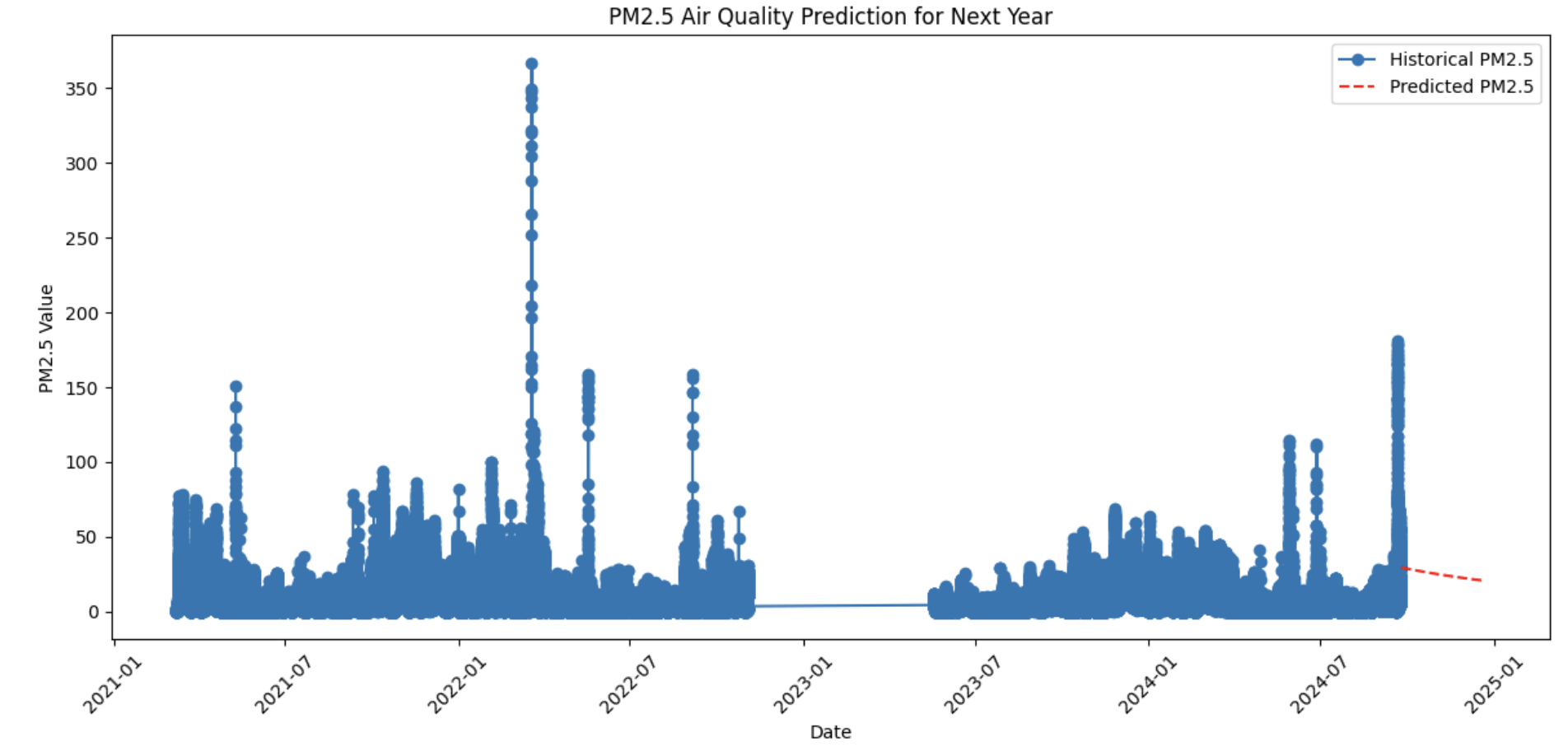
Прогнозовані дані демонструють більш стабільну функцію, ніж історичні дані і вказують на поступове зниження протягом наступних 90 днів. Додавання нових ознак (у вектор X) та зміна моделі можуть покращити результати прогнозування.
3.6. Задачі для самостійної роботи
Пропонуємо самостійно вирішити кілька задач, щоб закріпити базові навички програмування на Python.
Задача 1: Сума парних чисел
Є список чисел. Потрібно обчислити суму тільки парних чисел зі списку.
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]even_sum = 0for number in numbers: if number % 2 == 0: even_sum += numberprint("Сума парних чисел:", even_sum)
Результат виконання коду:
Сума парних чисел: 30
Задача 2: Знайти найбільше число
Є список чисел. Потрібно знайти найбільше число в цьому списку.
numbers = [12, 5, 33, 7, 20, 55, 10]max_number = numbers[0]for number in numbers: if number > max_number: max_number = numberprint("Найбільше число:", max_number)
Результат виконання коду:
Найбільше число: 55
Задача 3: Підрахунок голосних букв
Є рядок. Потрібно підрахувати кількість голосних букв (a, e, i, o, u) у цьому рядку.
string = "This is a simple string"vowels = "aeiou"count = 0for char in string: if char.lower() in vowels: count += 1print("Кількість голосних букв:", count)
Результат виконання коду:
Кількість голосних букв: 6
Задача 4: Перетворення чисел в список рядків
Є список чисел. Потрібно перетворити кожне число в рядок.
numbers = [1, 2, 3, 4, 5]string_numbers = [str(number) for number in numbers]print("Список рядків:", string_numbers)
Результат виконання коду:
Список рядків: ['1', '2', '3', '4', '5']
Задача 5: Пошук елементів, що діляться на 3
Є список чисел. Потрібно знайти всі числа, що діляться на 3.
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]divisible_by_three = [number for number in numbers if number % 3 == 0]print("Числа, що діляться на 3:", divisible_by_three)
Результат виконання коду:
Числа, що діляться на 3: [3, 6, 9]
Задача 6: Пошук всіх пар чисел
Є список чисел. Потрібно знайти всі числа, які є парними.
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]even_numbers = [number for number in numbers if number % 2 == 0]print("Парні числа:", even_numbers)
Результат виконання коду:
Парні числа: [2, 4, 6, 8, 10]
Задача 7: Знайти позицію заданого елементу
Є список і заданий елемент. Потрібно знайти індекс цього елемента у списку.
numbers = [10, 20, 30, 40, 50]element_to_find = 30position = numbers.index(element_to_find)print("Індекс елемента:", position)
Результат виконання коду:
Індекс елемента: 2
Задача 8: Підрахунок кількості входжень елемента
Є список, і потрібно підрахувати, скільки разів заданий елемент зустрічається у списку.
numbers = [1, 2, 3, 2, 4, 2, 5, 2]element_to_count = 2count = numbers.count(element_to_count)print("Кількість входжень елемента:", count)
Результат виконання коду:
Кількість входжень елемента: 4
Задача 9: Перевернути список
Є список чисел. Потрібно перевернути його.
numbers = [1, 2, 3, 4, 5]reversed_numbers = list(reversed(numbers))print("Перевернутий список:", reversed_numbers)
Результат виконання коду:
Перевернутий список: [5, 4, 3, 2, 1]
Задача 10: Видалити дублікати зі списку
Є список чисел. Потрібно видалити всі дублікати і залишити лише унікальні елементи.
numbers = [1, 2, 2, 3, 4, 4, 5]unique_numbers = list(set(numbers))print("Список без дублікатів:", unique_numbers)
Результат виконання коду:
Список без дублікатів: [1, 2, 3, 4, 5]
Задача 11: Фільтрація списку
Є список чисел. Створіть новий список, який містить лише числа більше 5.
numbers = [3, 7, 2, 9, 1, 10, 4]filtered_numbers = []for number in numbers: if number > 5: filtered_numbers.append(number)print("Числа більше 5:", filtered_numbers)
Результат виконання коду:
Числа більше 5: [7, 9, 10]
Задача 12: Факторіал числа
Напишіть програму, яка обчислює факторіал заданого числа.
n = 5factorial = 1for i in range(1, n + 1): factorial *= iprint("Факторіал числа", n, "дорівнює", factorial)
Результат виконання коду:
Факторіал числа 5 дорівнює 120
4. Інструменти роботи в команді
У сучасному світі проєктної роботи та командної співпраці існує багато інструментів, які спрощують роботу команди та допомагають ефективніше досягати спільних цілей. Ці інструменти можна поділити на дві основні категорії:
- Технічні інструменти – такі як GitHub, які забезпечують можливості для управління вихідним кодом, зберігання проєктів, контролю версій та спільної розробки.
- Організаційні інструменти – це методології роботи в команді, які допомагають організувати ефективну роботу групи. Наприклад, методологія Kanban дозволяє візуалізувати процес виконання завдань, контролювати потік роботи та підвищувати ефективність команди.
У цьому розділі ми зосередимося на таких інструментах, як GitHub, який дозволяє спільно працювати над програмним кодом проєкту, та FreedCamp як приклад платформи для проєктного менеджменту. Ми навчимося керувати проєктами за допомогою методології Kanban, працювати з цими платформами та набувати практичних навичок як в управлінні вихідним кодом, так і в організації командної роботи.
4.1. GitHub як технічний інструмент для командної роботи
GitHub — це потужний інструмент для управління вихідним кодом і контролю версій. Він використовується для зберігання, відстеження та інтеграції змін у проєктах програмного забезпечення. GitHub дозволяє командам розробників спільно працювати над одним проєктом, забезпечуючи зручні засоби для координації роботи та збереження змін.
Системи контролю версій
Введення в Git
Git — це система контролю версій, яка дозволяє командам ефективно працювати над одним проєктом, відстежуючи зміни в коді, об’єднуючи правки та уникаючи конфліктів. Це ключовий інструмент для командної роботи в сучасній розробці програмного забезпечення.
Робота з гілками в Git: Створення та злиття
Гілки у Git дозволяють створювати незалежні версії проєкту для розробки нових функцій чи виправлення помилок. Після завершення роботи ці гілки можна злити з основною, інтегруючи зміни в основний код.
Практична робота: Створення облікового запису GitHub та репозиторію
Завдання:
- Створити обліковий запис на GitHub
- Налаштувати новий репозиторій для зберігання проєктного коду. Це перший крок для початку роботи з системою контролю версій.
- Створити репозиторій під назвою "ai-projects" із одним файлом під назвою README, в якому написати текст: "В цьому репозиторії будуть розміщені мої навчальні проєкти"
Завантажити приклад проєкту для персонального портфоліо проєктів
4.2. Методології командної роботи
Методології командної роботи — це системні підходи до організації роботи, які допомагають структурувати процеси, підвищувати ефективність і досягати поставлених цілей у стислі терміни. У сфері командної роботи, особливо в розробці програмного забезпечення, методології є невіддільною частиною успішного виконання проєктів. Вони забезпечують чітке розуміння того, як команда має працювати, які завдання виконувати, та як організувати взаємодію між учасниками.
Kanban
Kanban — це методологія управління завданнями, яка допомагає організувати робочий процес і візуалізувати етапи виконання проєкту. Спочатку створена для оптимізації виробничих процесів, Kanban була адаптована для програмної розробки та інших сфер, де потрібна ефективна співпраця і постійний потік завдань.
Ключові принципи Kanban:
Візуалізація роботи.
Kanban-дошка дозволяє командам бачити всі завдання і їхній статус. Зазвичай дошка має кілька колонок, таких як "Задачі", "В процесі" і "Завершено". Завдання переміщуються між колонками у міру виконання.Обмеження задач "в процесі виконання".
Kanban обмежує кількість завдань, які виконуються одночасно, щоб уникнути перенавантаження команди. Це дозволяє зосереджуватись на завершенні поточних завдань.Керування потоком задач.
Замість того щоб керувати людьми, Kanban регулює потік задач. Це допомагає краще контролювати час, необхідний для виконання кожного завдання.Постійне покращення.
Kanban заохочує команди регулярно аналізувати та вдосконалювати свій робочий процес для підвищення ефективності та продуктивності.
Як працює Kanban-дошка
Kanban-дошка — це візуальний інструмент, який показує весь робочий процес. Вона поділена на кілька колонок, які відображають різні етапи виконання завдань. Наприклад:
- Задачі — завдання, які ще не розпочаті.
- В процесі — завдання, які виконуються зараз.
- Завершено — завдання, які вже виконані.
Команда додає завдання до дошки та переміщує їх між колонками у міру виконання. Це дозволяє швидко оцінювати, скільки завдань перебуває на кожному етапі, і виявляти можливі затримки.
Інші методології: Scrum
Крім Kanban, популярною є методологія управління проєктами Scrum. Вона зосереджена на коротких циклах (так званих "спринтах") і включає чітко визначені ролі та ритуали, такі як щоденні зустрічі й ретроспективи. Вона є більш складною і може використовуватись там, де потрібна чітка організація праці. У цьому розділі ми все ж фокусуємось на Kanban як основному інструменті для організації командної роботи, який є підходящим у більшості випадків.
Розберемось із Kanban на практиці: реєструємось на FreedCamp
FreedCamp — це платформа, яка дозволяє ефективно організувати роботу команди, розподіляючи проєкт на конкретні завдання та призначаючи їх відповідальним особам. За допомогою FreedCamp можна використовувати Kanban-методологію, яка допомагає відстежувати статус завдань і прогрес команди, візуалізуючи кожен етап роботи. Це забезпечує зручний огляд стану проєкту і дозволяє вчасно координувати дії команди.
Як зареєструватися на платформі FreedCamp
Відвідайте сайт FreedCamp https://freedcamp.com/uk/
На головній сторінці натисніть кнопку "Почати безкоштовно"
Ви можете зареєструватися за допомогою облікових записів Google, Facebook, Twitter або LinkedIn. Якщо ви бажаєте створити обліковий запис без прив’язки до соціальних мереж, натисніть "або зареєструватися за допомогою електронної пошти"
Після виконання цих кроків ваш обліковий запис буде створено, і ви зможете почати роботу з проєктами на платформі FreedCamp.
Для вчителя: Робота в групах
Щоб організувати роботу в групах на платформі FreedCamp, спочатку створіть основну групу класу. Після реєстрації зайдіть до розділу "Groups" і натисніть "Create New Group". Вкажіть назву групи (наприклад, "11 клас") та додайте учнів, використовуючи їхні електронні адреси. Після запрошення всі учні отримають доступ до цієї основної групи.
Для створення проєктів команд зайдіть у групу класу і створіть окремі проєкти для кожної команди, наприклад, "Команда 1", "Команда 2" і так далі. Хоча всі учні матимуть доступ до всіх проєктів, завдання кожної команди можна чітко визначити в їхньому проєкті. Також можна призначити відповідальних за конкретні завдання, щоб кожна команда зосереджувалася на своїй частині роботи.
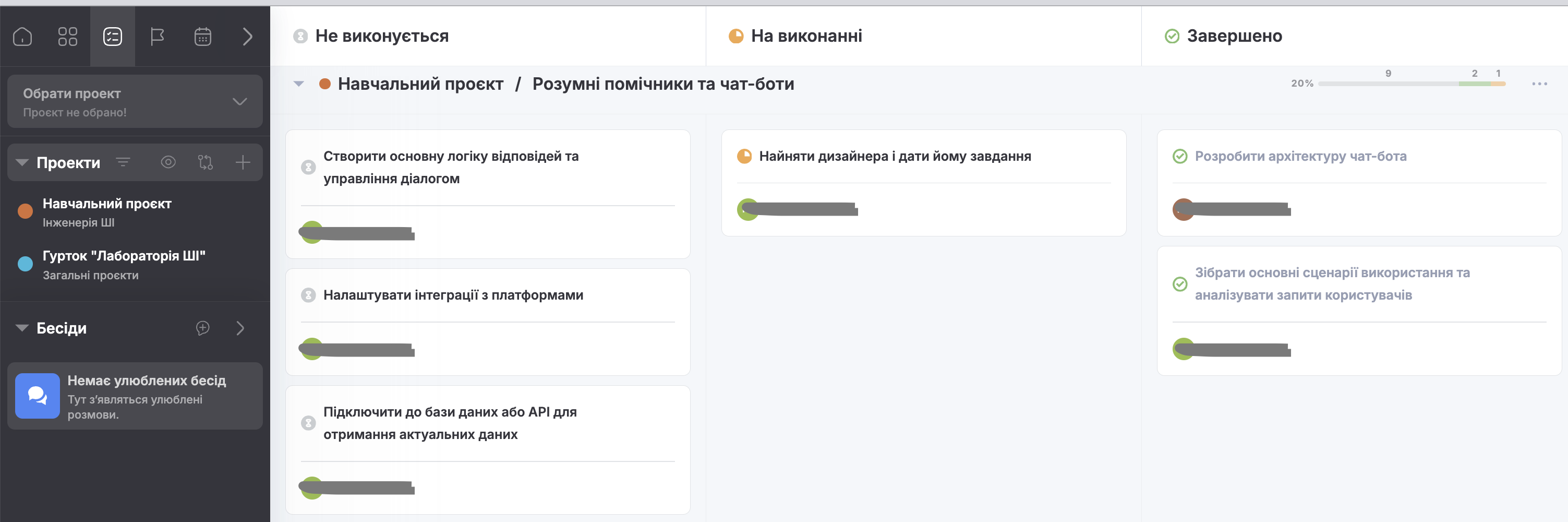
4.3. Лабораторна робота-воркшоп: Командна робота над технологічним стартапом
Цей воркшоп допоможе учасникам навчитися працювати в командах над розробкою технологічного стартапу, імітуючи дистанційну роботу. Учасники розподіляють ролі, обирають тему проєкту, планують завдання, працюють у віртуальному середовищі Freedcamp і навчаються ефективно комунікувати у форматі онлайн-зустрічей.
Підготовка
Для проведення воркшопу необхідно підготувати:
- Картки з ролями (наприклад, з платформи AI4GA Careers);
- Доступ до платформи Freedcamp;
- Комп'ютери або смартфони для всіх учасників.
Хід воркшопу
Розподіл ролей
- Кожен учасник отримує кар'єрну картку, що описує його роль у команді (наприклад, розробник, дизайнер, менеджер тощо).
- Протягом 5 хвилин учасники ознайомлюються з описом своєї ролі.
Розподіл на команди
- Учасники розбиваються на команди по 3-5 осіб. Рекомендується формувати команди так, щоб ролі були різноманітними.
- Кожна команда обирає тему технологічного стартапу та тімліда.
- Учасники кожної команди займають місця у класі на максимальній відстані один від одного (учасники команди не мають сидіти поряд), щоб імітувати дистанційну роботу.
- Тімліди підходять до вчителя для створення командних чатів у Freedcamp.
- Учасники працюють у командах, спілкуючись виключно через чат у Freedcamp.
- Що 15 хвилин проводиться "стендап":
- Командам дозволено поспілкуватись вживу, вони можуть зібратись разом і обговорити свою роботу голосом (до 3 хвилин).
- Після обговорення всі повертаються до дистанційної роботи.
- Цикл "робота – стендап" повторюється 4 рази.
Завершення воркшопу
- Після завершення роботи команди презентують свої стартапи, використовуючи перелік задач, які вони створили.
Цей воркшоп дозволяє учасникам на практиці відчути рольову взаємодію в команді, освоїти принципи дистанційної роботи та розвинути навички комунікації й організації проєкту.
4.4. Питання для самоперевірки
Що таке методологія роботи в команді і яка її мета?
- Це набір правил для написання коду.
- Це спосіб організації процесів у команді для досягнення ефективності.
- Це лише формальний документ для сертифікації компанії.
- Це набір технічних інструкцій для інженерів.
Що є основою Kanban-дошки?
- Таблиця з розподілом завдань на стовпці (наприклад, "To Do", "In Progress", "Done").
- Документ для детального планування проєкту.
- Програма для проєктного менеджменту.
- Схема взаємодії між членами команди.
Що допомагає Kanban-дошка покращити в команді?
- Візуалізацію виконання задач та управління завантаженням працівників.
- Автоматизацію написання коду.
- Підбір персоналу для команди.
- Звітування перед керівництвом.
Яка роль в команді відповідає за спілкування з клієнтами та опис вимог до продукту?
- Менеджер продукту
- Програміст
- Інженер-робототехнік
- Системний адміністратор
Чому важливо правильно розподіляти ролі в ІТ-команді?
- Щоб уникнути дублювання обов'язків і підвищити ефективність роботи.
- Щоб кожен міг виконувати всі ролі одночасно.
- Щоб працювати без дедлайнів.
- Щоб уникнути взаємодії між членами команди.
Яка основна роль Machine Learning Engineer у команді?
- Розробка моделей машинного навчання та їхня інтеграція у програми.
- Налаштування серверів для навчання моделей.
- Виконання аналізу даних для створення звітів.
- Написання документації до програм.
Чим відрізняється робота AI Researcher від Machine Learning Engineer?
- AI Researcher зосереджений на теоретичних дослідженнях, тоді як Machine Learning Engineer займається практичною реалізацією.
- AI Researcher займається виключно підтримкою роботи моделей на серверах компанії.
- Machine Learning Engineer пише статті у блог компанії, а AI Researcher тестує програми.
- Їхня робота повністю збігається.
Чим Machine Learning Engineer може допомогти AI Researcher у роботі?
- Перетворити теоретичні розробки на практичні реалізації.
- Допомогти створити звіти для менеджерів.
- Провести технічні співбесіди для нових працівників.
- Налаштувати дизайн для презентацій.
- Зіставте поняття із його визначенням
Поняття:
- Задача
- Менеджер
- Методологія управління проєктами
- Machine Learning Engineer
- Обробка природної мови (Natural Language Processing - NLP)
- Комп’ютерний зір (Computer Vision)
- Чат-бот
- Робот
Визначення:
- Це конкретна робота або дія, яку необхідно виконати для досягнення поставленої мети. Зазвичай має опис, дедлайн і відповідального.
- Це фахівець, який координує роботу команди, контролює виконання задач і дотримання дедлайнів, а також забезпечує ефективну комунікацію між усіма учасниками проєкту.
- Це набір принципів, підходів і правил, які визначають, як організовується, планується і виконується робота над проєктом.
- Фахівець, який розробляє, тестує та впроваджує моделі машинного навчання, забезпечуючи їх інтеграцію у програмні продукти.
- Це напрямок штучного інтелекту, який займається автоматизованою обробкою та аналізом текстів або мови, зокрема розпізнаванням, перекладом чи генерацією тексту.
- Це напрямок у штучному інтелекті, який займається автоматичним аналізом, обробкою та розпізнаванням зображень або відео.
- Програма, яка використовує штучний інтелект для спілкування з людьми через текст або голос.
- Машина, яка може виконувати завдання, керуючись програмою або штучним інтелектом.
5. Комп'ютерний зір
 Комп'ютерний зір — це галузь штучного інтелекту, яка дозволяє комп’ютерам "бачити" та розуміти візуальну інформацію з навколишнього світу. За допомогою спеціальних алгоритмів комп’ютери аналізують зображення, відео чи інші
Комп'ютерний зір — це галузь штучного інтелекту, яка дозволяє комп’ютерам "бачити" та розуміти візуальну інформацію з навколишнього світу. За допомогою спеціальних алгоритмів комп’ютери аналізують зображення, відео чи інші
візуальні дані та виконують завдання, які зазвичай потребують людського зору.

5.1. Бібліотека OpenCV
![]() OpenCV (Open Source Computer Vision Library) — це одна з найпопулярніших бібліотек з відкритим кодом для роботи з комп’ютерним зором і обробкою зображень. Вона надає широкий набір інструментів і функцій для аналізу зображень, відео, виявлення об’єктів та інших завдань, пов’язаних із візуальною інформацією.
OpenCV (Open Source Computer Vision Library) — це одна з найпопулярніших бібліотек з відкритим кодом для роботи з комп’ютерним зором і обробкою зображень. Вона надає широкий набір інструментів і функцій для аналізу зображень, відео, виявлення об’єктів та інших завдань, пов’язаних із візуальною інформацією.
Працювати із нею ми почнемо за допомогою інструменту Пісочниця OpenCV.
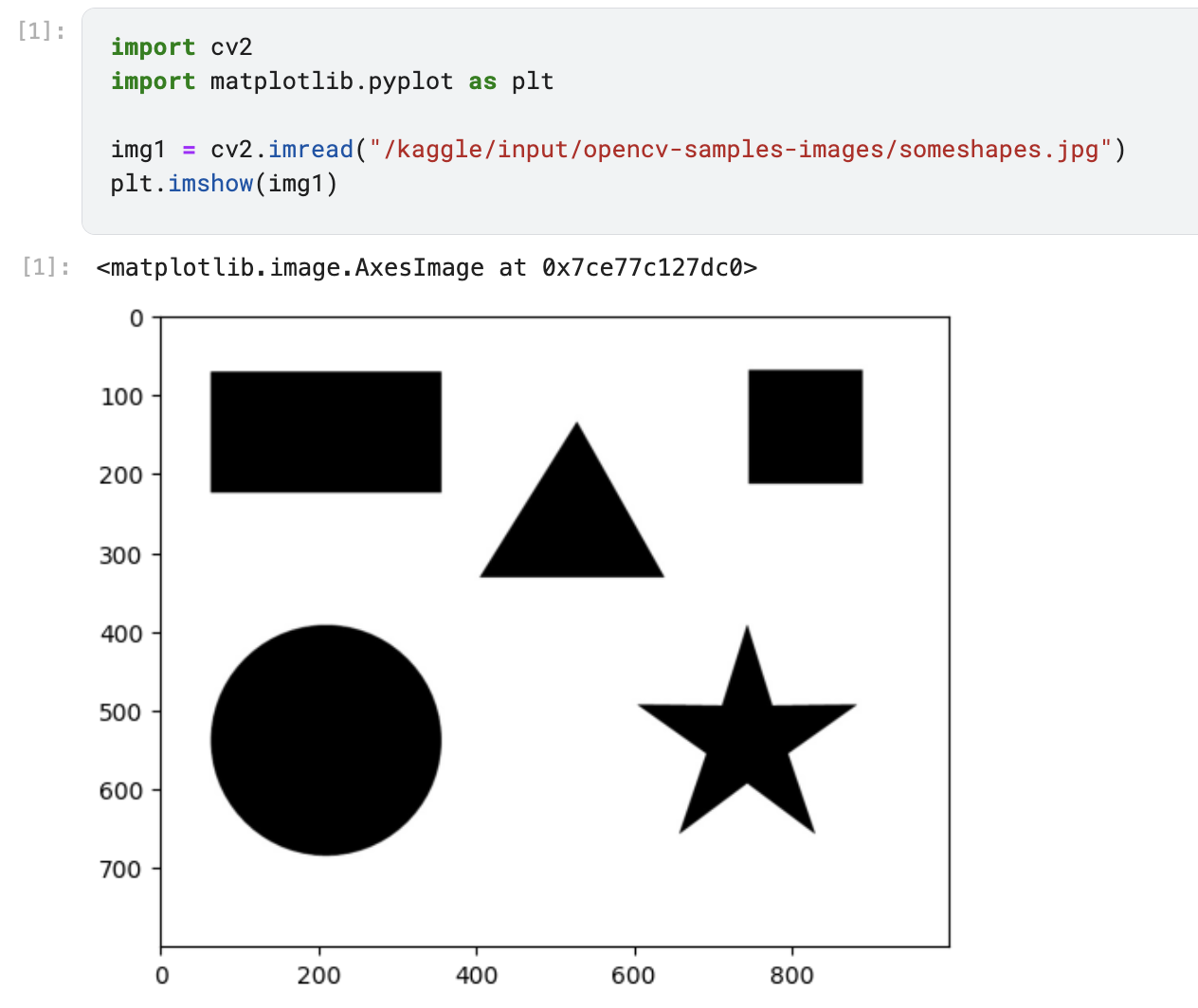
OpenCV дозволяє легко працювати із зображеннями. Почнемо з читання файлу. Для цього використаємо зображення з набору даних OpenCV Sample Images, доступного на Kaggle.
- Відкрийте набір даних і створіть новий ноутбук, натиснувши кнопку "New Notebook".
- Для читання зображення виконаємо наступний код:
import cv2import matplotlib.pyplot as pltimg1 = cv2.imread("/kaggle/input/opencv-samples-images/someshapes.jpg")plt.imshow(img1)
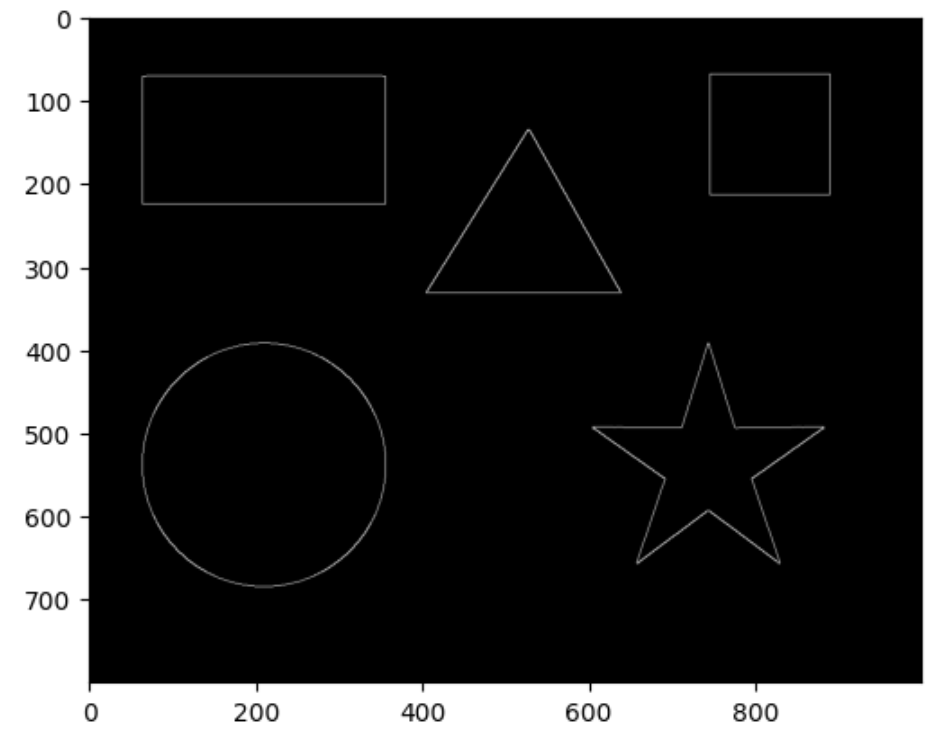
OpenCV містить багато корисних алгоритмів для обробки зображень. Одним з них є пошук контурів алгоритмом Кенні (Canny). Виконайте наступний код:
img = cv2.Canny(img1, 50, 50)plt.imshow(img, cmap="gray")
Перетворення кольорів
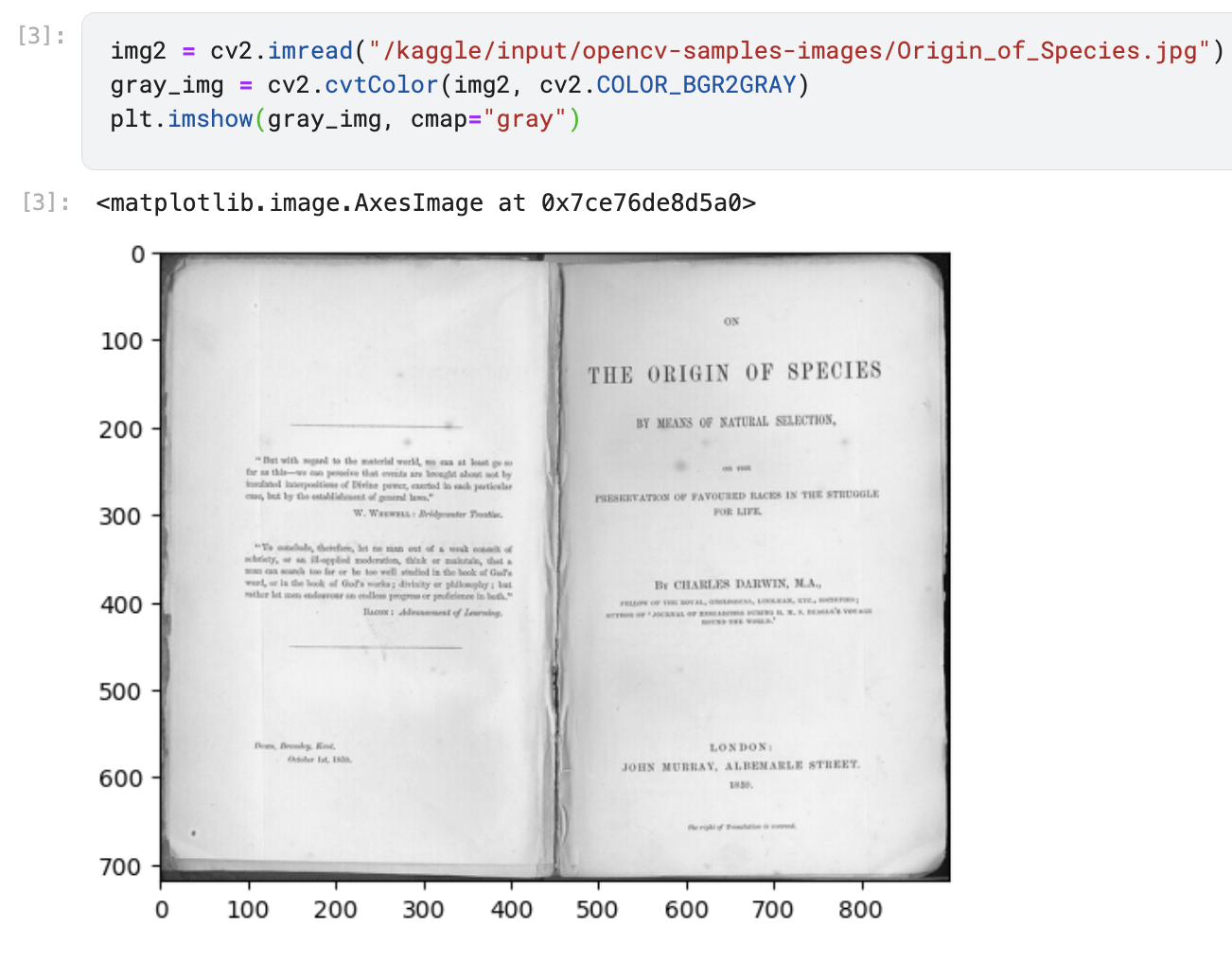
OpenCV дозволяє легко перетворювати зображення в різні кольорові простори, і у наступних розділах ви побачите у яких ситуаціях це може бути корисним. Наприклад, конвертуємо інше зображення на відтінки сірого. Виконаємо наступне:
- Прочитаємо зображення Origin_of_Species.jpg з набору даних.
- Використаємо функцію
cv2.cvtColorдля перетворення кольорового зображення у відтінки сірого.
img2 = cv2.imread("/kaggle/input/opencv-samples-images/Origin_of_Species.jpg")gray_img = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)plt.imshow(gray_img, cmap="gray")
Зміна розміру та малювання на зображенні
Для роботи із зображеннями часто потрібно змінювати їхній розмір або додавати графічні елементи. OpenCV надає зручні функції для цього. Розглянемо приклад:
- Змінимо розмір зображення.
- Намалюємо прямокутник поверх зображення.
resized_img = cv2.resize(img1, (300, 300))cv2.rectangle(resized_img, (50, 50), (250, 250), (0, 255, 0), 3)plt.imshow(resized_img, cv2.COLOR_BGR2RGB)
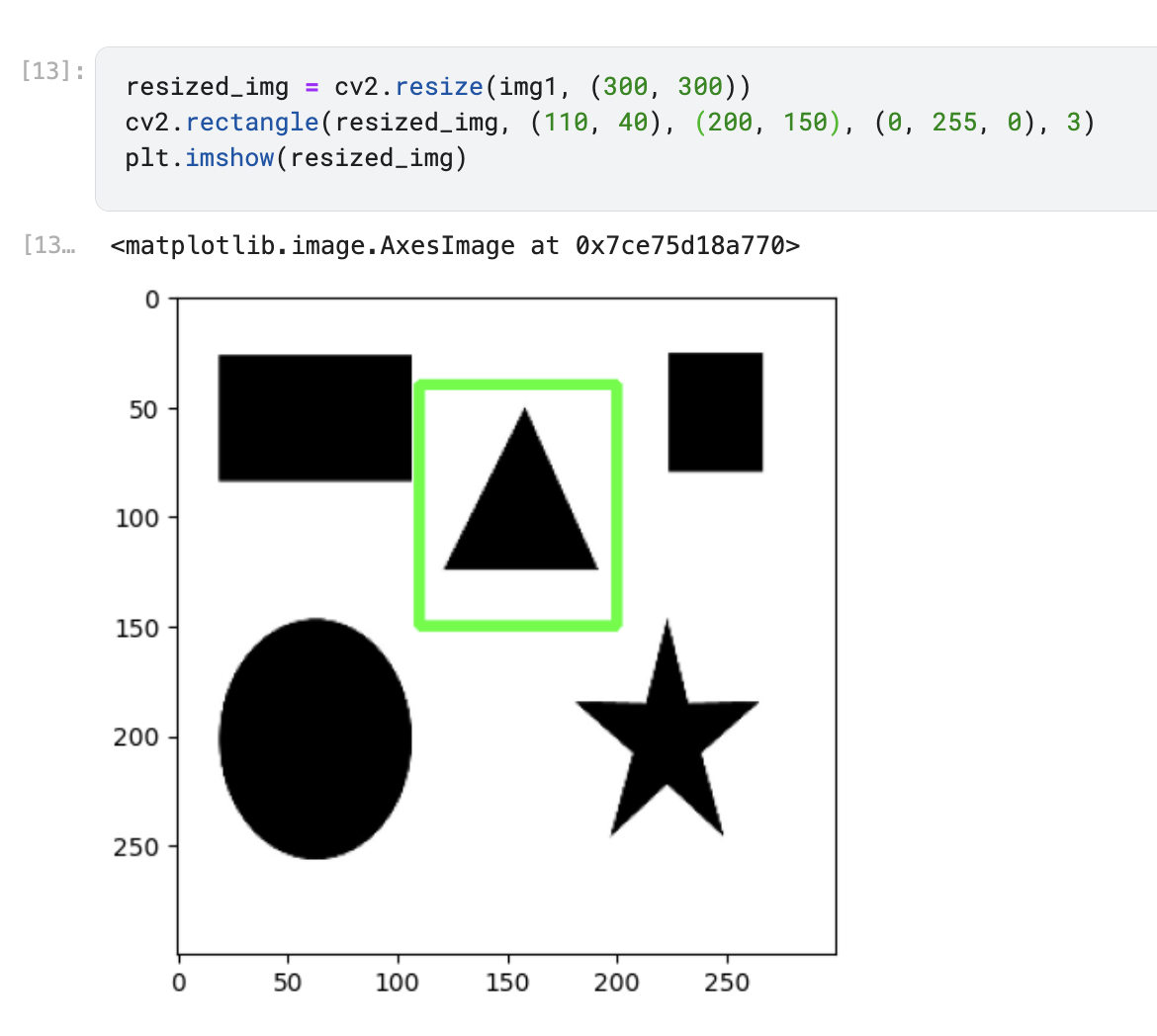
5.2. Практична робота
Завдання №1: Знайди зірку
- Відкрийте пісочницю https://www.rmn.pp.ua/ai-lab-sandbox/
- Оберіть завдання "Знайди зірку"
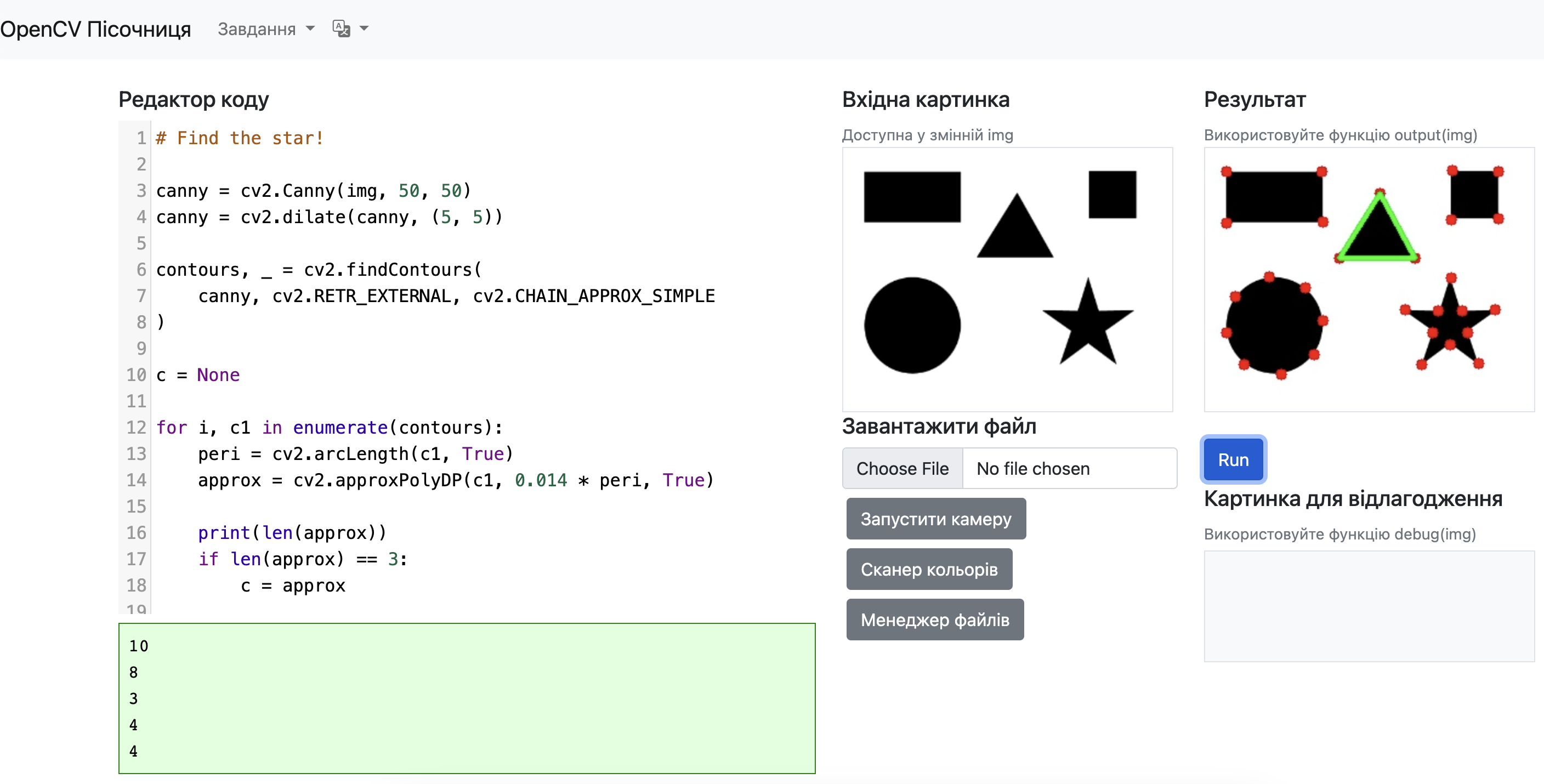
Давайте розберемо приклад коду із цього завдання по рядочках:
TBD😅5.3. Практична робота: Автомобільні номери. Шукаємо прямокутні фігури.
Розпізнавання номерів машин
Набір даних: https://www.kaggle.com/datasets/andrewmvd/car-plate-detection
https://www.kaggle.com/datasets/jaidalmotra/road-sign-detection
https://www.kaggle.com/code/rrader93/notebook6b2ff1f3a1/edit
5.4. Практична робота: Аналіз крові. Працюємо із кольорами та контурами.
Розпізнавання клітин крові: фільтрація по кольору
Мета роботи
Навчитися використовувати кольорову фільтрацію у просторі HSV для виділення об'єктів на зображенні, будувати контури знайдених об'єктів та програмно підраховувати їх кількість.
Завдання
- Створіть ноутбук із набору даних з зображеннями мікроскопії крові за допомогою OpenCV: https://www.kaggle.com/datasets/unclesamulus/blood-cells-image-dataset
- Прочитайте картинку /kaggle/input/blood-cells-image-dataset/bloodcells_dataset/basophil/BA_100102.jpg
- Перетворіть зображення у кольоровий простір HSV (
cv2.cvtColor(img, cv2.COLOR_BGR2HSV)). - Задайте діапазони кольорів для фільтрації певного типу клітин (наприклад, червоних або білих кров'яних тілець).
- Виконайте побудову маски за допомогою функції
cv2.inRange()для виділення об'єктів заданого кольору. - Знайдіть контури об'єктів на зображенні за допомогою
cv2.findContours(). - Намалюйте знайдені контури зеленим кольором на оригінальному зображенні (
cv2.drawContours()). - Підрахуйте кількість знайдених клітин і виведіть результат у програмі.
- Збережіть зображення з нанесеними контурами та зробіть скріншот роботи програми.
Що здати
- Скриншот зображення, де клітини виділені зеленими контурами.
- Вивід у програмі, який містить кількість знайдених клітин.
Використовуйте Python та бібліотеку OpenCV для виконання завдання.
https://www.kaggle.com/code/rrader93/contours-1/edit
Світлофори
https://www.kaggle.com/code/rrader93/notebook4cd6840fe6/edit
5.5. Самостійна робота
У цьому завданні ми будемо рахувати кількість риб на зображенні за допомогою двох основних методів комп'ютерного зору:

1. Пошук об'єктів за кольором у просторі HSV (Hue, Saturation, Value - Тон, Насиченість, Яскравість). HSV є більш зручним для пошуку кольорів ніж RGB, оскільки він розділяє інформацію про колір (тон) від інформації про освітленість. Це дозволяє більш точно визначати потрібний колір навіть при різному освітленні.
import cv2
import numpy as np
# Зчитуємо зображення
img = cv2.imread('fish.jpg')
# Конвертуємо зображення з BGR у HSV
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# Визначаємо діапазон кольору риб (наприклад, помаранчевий)
# H: 10-20 для помаранчевого відтінку
# S: 100-255 щоб уникнути дуже блідих кольорів (при S<100 колір майже білий)
# V: 100-255 щоб уникнути дуже темних кольорів (при V<100 колір майже чорний)
lower_orange = np.array([10, 100, 100]) # Нижня межа HSV
upper_orange = np.array([20, 255, 255]) # Верхня межа HSV
# Створюємо маску для виділення об'єктів заданого кольору
mask = cv2.inRange(hsv, lower_orange, upper_orange)2. Фільтрація знайдених об'єктів за площею (contourArea) - це дозволяє відфільтрувати занадто малі або великі об'єкти, залишивши лише ті, що відповідають розміру риб. Наприклад:
import cv2
import numpy as np
# Знаходимо контури об'єктів
contours, _ = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Фільтруємо контури за площею
MIN_AREA = 500 # мінімальна площа об'єкта
MAX_AREA = 5000 # максимальна площа об'єкта
filtered_contours = []
for contour in contours:
area = cv2.contourArea(contour)
if MIN_AREA < area < MAX_AREA:
filtered_contours.append(contour)
# Кількість знайдених риб
fish_count = len(filtered_contours)Спробуйте самі порахувати кількість риб: https://www.rmn.pp.ua/ai-lab-sandbox/#
5.6. Фільтри обличчя
Фільтри обличчя - це популярний приклад застосування комп'ютерного зору, який ми часто зустрічаємо в соціальних мережах та месенджерах. В цьому практичному завданні ми розглянемо, як створювати такі фільтри за допомогою технології Haar Cascade.
Haar Cascade - це алгоритм машинного навчання для виявлення об'єктів на зображенні, який особливо ефективний для розпізнавання облич. Алгоритм використовує каскад простих класифікаторів для поступового виявлення характерних рис обличчя.
OpenCV вже містить набір попередньо навчених каскадів Haar, які можна одразу використовувати у своїх проектах. Серед них є каскади для виявлення:
- Облич (frontalface)
- Очей
- Посмішки
- Верхньої частини тіла
Ці каскади знаходяться в папці data/haarcascades бібліотеки OpenCV і мають розширення .xml. Наприклад, для виявлення облич можна використовувати файл haarcascade_frontalface_default.xml.
В нашому практичному завданні ми будемо:
- Отримувати відео з веб-камери в реальному часі
- Використовувати Haar Cascade для виявлення облич у кадрі
- Накладати різні візуальні ефекти та маски на виявлені обличчя
Щоб спробувати створити власний фільтр обличчя, перейдіть за посиланням: https://www.rmn.pp.ua/ai-lab-sandbox/ та оберіть завдання "Фільтри обличчя". Після цього натисніть кнопку "Запустити камеру", щоб почати обробляти зображення з вашої веб-камери в реальному часі.
Приклад проєкту із застосуванням OpenCV та фільтрів обличчя
5.7. Тест
- Що таке компʼютерний зір?
- Система для автоматичного перекладу тексту
- Метод шифрування даних
- Програма для управління файлами
- Технологія, яка дозволяє комп'ютерам розпізнавати та аналізувати зображення або відео
- Який із наведених прикладів є застосуванням комп'ютерного зору?
- Пошук в інтернеті за ключовими словами
- Навігація безпілотних автомобілів
- Моделювання хімічних реакцій
- Аналіз текстових документів
- Яка функція використовується для читання зображення з файлу в OpenCV?
- cv2.image_read()
- cv2.show()
- cv2.imread()
- cv2.load()
- Як відобразити зображення у ноутбуці Kaggle за допомогою OpenCV?
- plt.display(img)
- cv2.plot(img)
- plt.imshow(img)
- cv2.imshow('Image', img)
- Яка функція OpenCV використовується для знаходження контурів на зображенні?
- cv2.detectContours()
- cv2.contourFind()
- cv2.findContours()
- cv2.findEdges()
- Як підрахувати кількість контурів на зображенні?
- len(contours)
- sum(contours)
- cv2.countContours(contours)
- count(contours)
- Який метод використовується для обчислення площі контуру?
- cv2.findArea(contour)
- cv2.area(contour)
- cv2.contourArea(contour)
- cv2.calculateArea(contour)
- Як зображення потрібно підготувати перед пошуком контурів?
- Конвертувати у формат PNG
- Інвертувати кольори
- Розмити за допомогою GaussianBlur
- Перетворити на градації сірого
- Після виклику cv2.imread() зображення автоматично конвертується у градації сірого.
- Правильно
- Неправильно
- OpenCV працює з координатами пікселів у форматі (x, y).
- Правильно
- Неправильно
- Чим більше пікселів у контурі, тим більша його площа.
- Правильно
- Неправильно
6. Практичне застосування ШІ
У цьому розділі пропонується:
- розпочати курс "Елементи ШІ", та пройти її першу частину "Вступ до ШІ"
- розібратись із тим, що таке експертні системи та спробувати створити власну
- як працює ШІ в компʼютерних іграх, та спробувати запрограмувати самостійно за допомогою https://www.codingame.com/ - платформи для "coding game".
6.1. Що таке ШІ?
Розділ: Що таке ШІ?
Як ми визначаємо ШІ? ШІ - це спосіб робити комп'ютери, що здатні виконувати людську роботу. Це означає, що вони можуть виконувати завдання, які раніше вимагали людського інтелекту, такі як розуміння мови, вирішення задач, розпізнавання образів і навіть самостійне прийняття рішень.
Вправа "Що є, а що не є ШІ?": https://courses.mooc.fi/org/elements-of-ai/courses/elements-of-ai-ukr/chapter-1/%D1%8F%D0%BA-%D0%BC%D0%B8-%D0%B2%D0%B8%D0%B7%D0%BD%D0%B0%D1%87%D0%B0%D1%94%D0%BC%D0%BE-%D0%A8%D0%86
6.2. Суміжні галузі та філософія ШІ
Розділ: Суміжні галузі
Як працюють нейронні мережі?
Нейронні мережі – це основа сучасного штучного інтелекту. Вони імітують роботу біологічних нейронів у мозку, складаючись із шарів взаємопов’язаних штучних нейронів.
Для кращого розуміння принципів роботи нейронних мереж ви можете скористатися інтерактивною платформою TensorFlow Playground (https://playground.tensorflow.org/). Тут можна експериментувати з параметрами мережі, кількістю шарів та типами активаційних функцій, щоб побачити, як вони впливають на точність навчання.
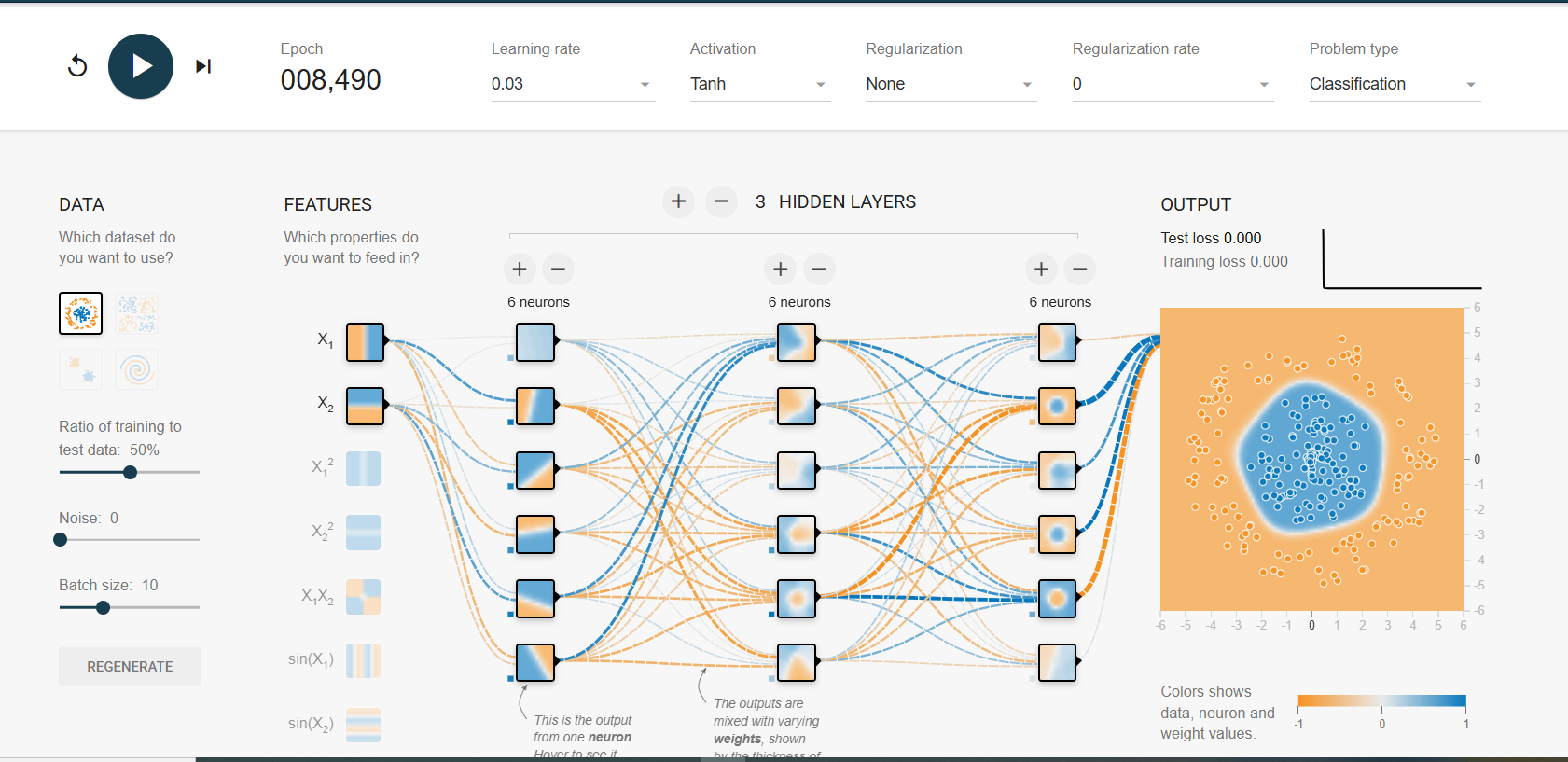
Глибокі нейронні мережі складаються з багатьох прихованих шарів, що дозволяє їм навчатися складним шаблонам і знаходити приховані залежності в даних.
Розділ: Філософія ШІ
Тест Тюрінга, запропонований у 1950 році британським математиком і логіком Аланом Тюрінгом, є одним із перших формальних критеріїв визначення, чи може машина проявляти інтелект. Суть тесту полягає в тому, що суддя спілкується через текстовий інтерфейс із двома співрозмовниками — людиною та комп’ютером.
Проте тест Тюрінга має серйозну філософську критику, серед найвідоміших аргументів є мисленневий експеримент "Китайська кімната", запропонований філософом Джоном Серлом у 1980 році: уявімо людину, яка не знає китайської мови, але перебуває в кімнаті з великою інструкцією, що дозволяє їй правильно відповідати на питання китайською, просто маніпулюючи символами за певними правилами. Ззовні може здаватися, що ця людина розуміє китайську, хоча насправді вона лише виконує алгоритмічні дії. Цей експеримент критикує ідею того, що імітація мови означає справжнє розуміння. Серл стверджує, що комп’ютери можуть обробляти символи, але не здатні мати справжню свідомість чи розуміння.
Таким чином, дебати щодо тесту Тюрінга та "Китайської кімнати" піднімають фундаментальні питання про природу мислення та розуміння. Вони досі залишаються актуальними у дискусіях про штучний інтелект, свідомість і межі машинного навчання.
А як ви думаєте? Чи достатньо здатності машини імітувати людську поведінку, щоб вважати її розумною? Чи можна вважати комп’ютер свідомим, якщо він пройде тест Тюрінга?
Дебати: Тест Тюрінга та Китайська кімната
Поділіться на три групи:
- Доповідачі – аргументують, що якщо машина може спілкуватися як людина і вводити інших в оману, то вона повинна вважатися інтелектуальною.
- Опоненти – стверджують, що тест перевіряє лише імітацію розуму, але не доводить наявність справжнього мислення чи свідомості.
- Рецензенти – аналізують аргументи обох сторін, оцінюють логіку, силу доказів та вказують на слабкі місця в аргументації.
Дискусія:
- Виступ доповідачів (2-3 хв) – пояснюють, чому тест Тюрінга є достатнім критерієм інтелекту.
- Відповідь опонентів (2-3 хв) – контраргументують, чому тест не доводить наявність свідомості.
- Питання від рецензентів – уточнюючі запитання обом сторонам.
- Друга хвиля обговорення – кожна сторона реагує на контраргументи та уточнює свої позиції.
- Доповідачі (2-3 хв)
- Опоненти (2-3 хв)
- Остаточне слово "Рецензентів" – підсумовують дискусію та висловлюють свою думку про те, яка команда була переконливішою.
Критерії оцінки:
- Логічність аргументів
- Використання прикладів
- Вміння відповідати на контраргументи
- Чіткість викладу думок
6.3. Експертні системи
Що таке експертні системи?
Експертні системи - це комп'ютерні програми, які імітують процес прийняття рішень людиною-експертом. Вони були одними з перших форм програмного забезпечення штучного інтелекту, що досягли комерційного успіху.
Історія експертних систем
Перші експертні системи з'явились у 1960-х роках. Найвідомішою була система DENDRAL (1965), розроблена в Стенфордському університеті для визначення молекулярної структури органічних сполук. Інша знаменита система - MYCIN (1970-ті), призначена для діагностики інфекційних захворювань крові.
Основні компоненти експертної системи:
- База знань (містить факти та правила)
- Механізм логічного виведення
- Інтерфейс користувача
- Модуль пояснень
Практичне застосування
Експертні системи можуть використовуватися в медичній діагностиці, фінансовому плануванні, технічній діагностиці, та навіть у криміналістиці - як ми побачимо в наступних практичних роботах.
Практична робота №1: "Таємниця зниклого трофея"
Сюжет
Після міського конкурсу талантів зник престижний Золотий трофей, який стояв на подіумі. Детектив Пролог береться за розслідування. Відомо, що злодієм міг бути лише той, хто був на місці злочину і мав мотив.
Підозрювані та докази
Джордан (Jordan)
- Шанована особа в громаді
- Не помічений на місці злочину
Кріс (Chris)
- Батько двох учасників конкурсу
- Стверджує, що пішов готувати частування
Алекс (Alex)
- Учасник конкурсу, який не переміг
- Помічений біля подіуму
- Бачив Блейка біля подіуму
- Мотив: засмучення через програш
Блейк (Blake)
- Брат Алекса
- Бачив Кейсі біля входу
- Має алібі
Кейсі (Casey)
- Друг Блейка
- Колекціонер трофеїв
- Була біля подіуму
- Мотив: бажання мати трофей
- Має алібі
Сем (Sam)
- Дитина Алекса
- Грався біля сцени
- Потенційний свідок
Тейлор (Taylor)
- Дитина Алекса
- Займалася малюванням
- Скоріш за все, не пов'язана зі злочином
person(jordan).
person(chris).
person(alex).
person(blake).
person(casey).
person(sam).
person(taylor).
closer(alex).
closer(casey).
see(alex, blake).
see(blake, casey).
motive(alex).
motive(casey).
alibi(casey).
alibi(blake).
% ПРАВИЛА
suspect(X) :- person(X), motive(X), closer(X).
witness(X) :- person(X), see(X, _).
guilty(X) :- suspect(X), \+ alibi(X).

Практична робота №2
Середовище розробки: https://swish.swi-prolog.org/
Опис ситуації
У мальовничому куточку старовинного села розташувався маєток, відомий як «Чарівний Маєток». Протягом останніх тижнів мешканці околиць почали говорити про дивні події: у темні, холодні ночі коридори маєтку нібито наповнювалися незбагненними звуками, а гості і працівники розповідали про появу загадкової фігури, схожої на привида. Проте, уважний персонал знав всі секретні ходи маєтку та відзначав, що ці історії – лише легенди, які могли відволікати увагу від справжніх подій.
Злочин
Одного зимового вечора, коли сніг повільно вкривав околиці, стався справжній злочин. З родинного сховища, яке зберігало безцінні коштовності, було вкрадено багато ювелірних виробів. Ретельний огляд місця злочину показав, що двері сховища були відчинені зсередини – немов би ніхто не хотів, щоб злам відразу викликав підозру.
Підозрювані та їх характеристики
- Андрій – позаштатний охоронець маєтку
- Відповідав за безпеку
- Не зміг чітко пояснити своє місцезнаходження під час злочину
- Бачив Костянтина за роботою в саду
- Олена – служниця маєтку
- Працює в маєтку понад 20 років
- Знає всі таємні ходи
- Має алібі - була в крамниці
- Деякі деталі викликають підозру
- Костянтин – садівник маєтку
- Часто переміщувався по території
- Був помічений біля сховища
- На одязі знайдено плями від мастила
- Павло – племінник власника
- Має фінансові труднощі
- Можливий мотив - крадіжка коштовностей
- Стверджує, що бачив привида
- Відсутні свідки його присутності
Завдання
За попередніми підказками детективне управління вирішило використати Prolog для реконструкції подій та аналізу доказів. Ваше завдання – створити базу знань, яка описує факти, пов'язані з місцезнаходженням підозрюваних, їх доступом до різних частин маєтку, наявними доказами та можливими мотивами.
6.4. Програмування ШІ для компʼютерних ігор
Одним із цікавих напрямків використання штучного інтелекту є створення ботів для комп’ютерних ігор. Це не лише дозволяє навчитися аналізувати ігрові ситуації, але й розвиває алгоритмічне мислення, навички оптимізації рішень та знайомить із реальними методами керування агентами в середовищах із динамічними змінами.
Для практичного вивчення цього напряму ми використаємо платформу Codingame (https://www.codingame.com/) – онлайн-середовище, що дозволяє програмістам розв’язувати алгоритмічні задачі та програмувати ботів. Однією з таких ігор є Mad Pod Racing, де учасники повинні програмувати штучний інтелект для керування кораблем у перегонах.
Coding game - гра "для програмістів", яка допомагає вдосконалювати навички програмування, розвивати логічне мислення та вирішувати складні задачі. Це відмінний спосіб покращити свої навички програмування, весело провести час і вивчити нові технології.
Завдання
- Зареєструватися на сайті Codingame.
- Відкрити гру Mad Pod Racing (https://www.codingame.com/multiplayer/bot-programming/mad-pod-racing).
- Використовуючи Python, потренуватися у створенні бота, який аналізуватиме ігрову ситуацію та прийматиме рішення щодо керування кораблем. Використовуйте підказки на сайті.
- Дослідити алгоритми керування, такі як пошук оптимального маршруту, прийняття рішень на основі поточного положення корабля та його швидкості.
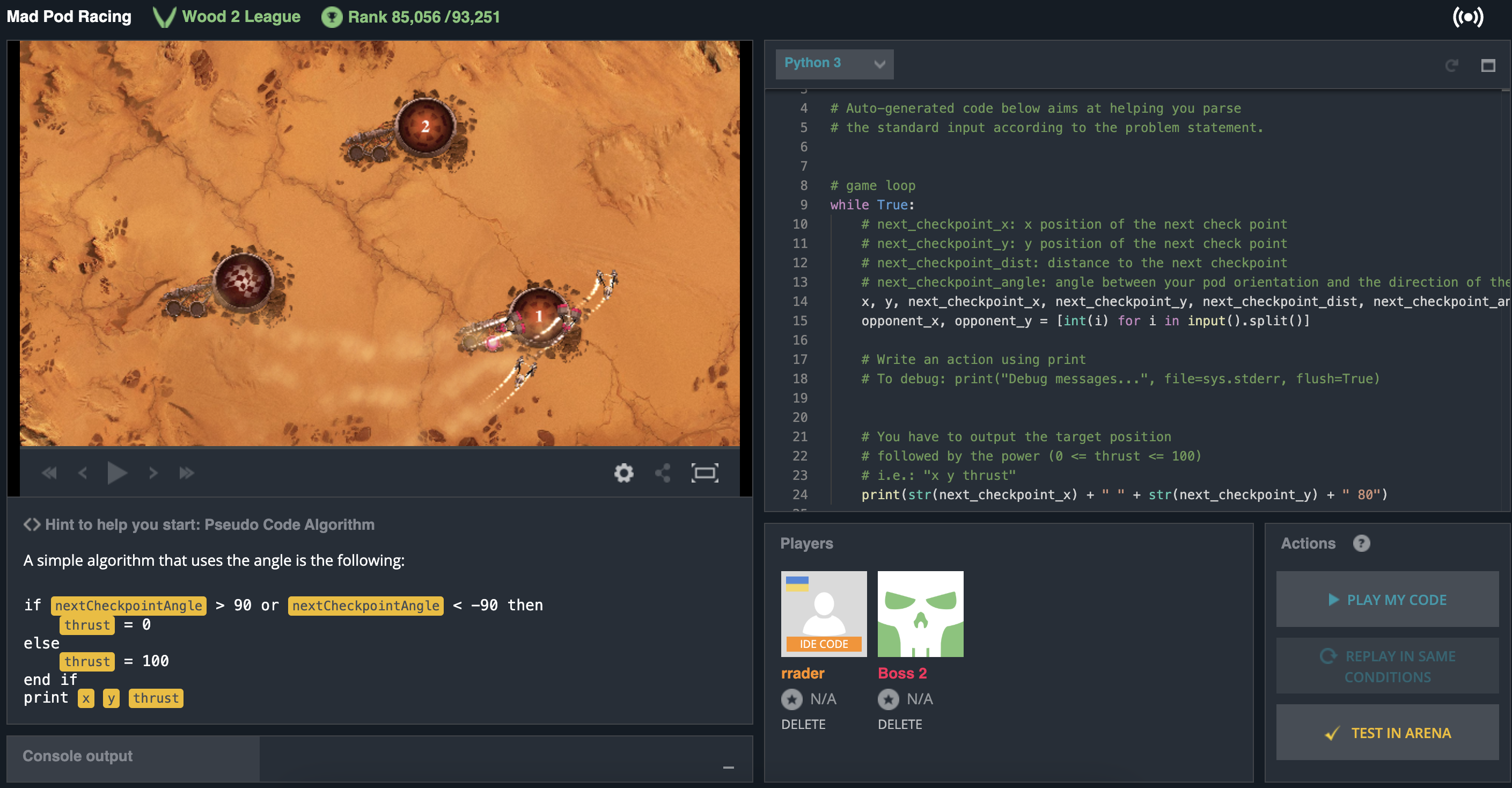
Інші "ігри для програмістів":
6.5. Практична робота: Телеграм-бот
Цей проєкт дозволяє створити Telegram-бота, який відповідатиме на запитання користувачів з гумором, використовуючи штучний інтелект через OpenRouter API.
1. Встановлення бібліотек
У терміналі GitHub Codespace виконайте наступну команду:
pip install telepot openai2. Отримання токенів
-
Telegram токен:
- Відкрийте @BotFather у Telegram
- Створіть нового бота командою
/newbot - Скопіюйте отриманий токен
-
OpenRouter API ключ:
- Перейдіть на openrouter.ai
- Зареєструйтесь або увійдіть
- У вкладці API Keys створіть новий ключ
- Скопіюйте ключ
3. Додавання секретів у GitHub Codespaces
У налаштуваннях репозиторію GitHub:
- Перейдіть до Settings → Secrets and variables → Codespaces Secrets
- Додайте два нові секрети:
| Назва | Значення |
|---|---|
TG_KEY |
Токен вашого Telegram-бота з BotFather |
OPENROUTER_KEY |
Ваш API ключ із openrouter.ai |
4. Створення файлу main.py
Створіть у корені проєкту файл main.py зі наступним вмістом:
import telepot
from telepot.loop import MessageLoop
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.environ["OPENROUTER_KEY"],
)
def message(msg):
content_type, chat_type, chat_id = telepot.glance(msg)
print(content_type, chat_type, chat_id)
completion = client.chat.completions.create(
model="openai/gpt-4o-mini",
messages=[
{"role": "system", "content": "Ти — бот, що відповідає з гумором на запитання."},
{"role": "user", "content": msg['text']}
]
)
bot.sendMessage(chat_id, completion.choices[0].message.content)
bot = telepot.Bot(os.environ["TG_KEY"])
MessageLoop(bot, {'chat': message}).run_forever()
5. Запуск бота
У терміналі виконайте:
python main.py6. Перевірка
- Відкрийте чат з вашим Telegram-ботом
- Надішліть будь-яке запитання
- Бот надасть відповідь з гумором
7. Математика для ШІ
У цьому розділі ми розглянемо основні математичні концепції, необхідні для розуміння та роботи зі штучним інтелектом:
- Лінійна алгебра - вивчимо основні операції з векторами та матрицями, які є фундаментальними для багатьох алгоритмів ШІ
- Теорія ймовірності - розберемо базові поняття ймовірності та методи генерації випадкових чисел
- Функції активації - познайомимося з одиничною ступінчастою функцією та її роллю в нейронних мережах
- Методи оптимізації - навчимося працювати з похибками, виконувати апроксимацію даних за допомогою лінійних та квадратичних функцій, оцінювати точність наближень
Додаткові матеріали для вивчення доступні на платформі Elements of AI:
https://courses.mooc.fi/org/elements-of-ai/courses/elements-of-ai-ukr/chapter-3
7.1. Лінійна алгебра
Вектори та матриці є фундаментальними поняттями в лінійній алгебрі та відіграють важливу роль у штучному інтелекті.
Вектори
Вектор - це впорядкований набір чисел. Наприклад: v = [1, 2, 3]
Основні операції з векторами:
- Додавання: [1,2] + [3,4] = [4,6]
- Множення на число: 2 × [1,2] = [2,4]
- Скалярний добуток: [1,2] · [3,4] = 1×3 + 2×4 = 11
Матриці
Матриця - це прямокутна таблиця чисел. Наприклад:
|1 2 3|
|4 5 6|
Основні операції з матрицями:
- Додавання матриць (поелементно)
- Множення матриці на число
- Множення матриць
- Транспонування (заміна рядків на стовпці)
У штучному інтелекті матриці часто використовуються для зберігання ваг нейронних мереж, а вектори - для представлення вхідних даних та результатів.
7.2. Навчання з підкріпленням
 Навчання з підкріпленням (Reinforcement Learning) - це тип машинного навчання, де агент навчається приймати рішення через взаємодію з середовищем. Агент отримує винагороди або штрафи за свої дії, і його мета - максимізувати сумарну винагороду.
Навчання з підкріпленням (Reinforcement Learning) - це тип машинного навчання, де агент навчається приймати рішення через взаємодію з середовищем. Агент отримує винагороди або штрафи за свої дії, і його мета - максимізувати сумарну винагороду.
Основні компоненти навчання з підкріпленням:
- Агент - система, що навчається і приймає рішення
- Середовище - світ, з яким взаємодіє агент
- Стан - поточна ситуація в середовищі
- Дія - що агент може зробити
- Винагорода - зворотній зв'язок від середовища

Q-Learning
Q-Learning - це один з найпопулярніших алгоритмів навчання з підкріпленням. Він базується на створенні Q-таблиці, яка зберігає очікувані винагороди для кожної пари стан-дія.
Q-Learning широко застосовується в:
- Робототехніці
- Ігрових системах
- Оптимізації ресурсів
- Автономному керуванні
Q-Learning для гри в хрестики-нолики
У випадку хрестиків-ноликів, Q-матриця буде мати наступний вигляд:
- Рядки - всі можливі стани дошки (приблизно 3^9 = 19683 стани)
- Стовпці - можливі дії (позиції від 0 до 8)
Наприклад, частина Q-матриці може виглядати так:
Стан дошки Дія 0 Дія 1 Дія 2 ... Дія 8
[_,_,_,_,_,_,_,_,_] 0.0 0.0 0.0 ... 0.0
[X,_,_,_,_,_,_,_,_] 0.0 0.4 0.3 ... 0.1
[X,O,_,_,_,_,_,_,_] 0.0 0.0 0.7 ... 0.2
Формула оновлення Q-значень
Q-значення оновлюються за формулою:
Q(s,a) = Q(s,a) + α[R + γ·max(Q(s',a')) - Q(s,a)]
де:
s - поточний стан
a - виконана дія
α - швидкість навчання (learning rate)
R - отримана винагорода
γ - коефіцієнт знецінення (discount factor)
s' - наступний стан
max(Q(s',a')) - максимальне Q-значення для наступного стану
Типові значення параметрів для хрестиків-ноликів:
- α = 0.1 - 0.3 (повільне навчання для кращої збіжності)
- γ = 0.9 - 0.95 (високе значення, бо важливі довгострокові наслідки)
- R = 1 (перемога), -1 (програш), 0 (нічия або проміжний хід)
7.3. Практикум Python
Завдання для практики на E-Olymp- Скласти слово (#8993)
- Кількість речень (#8980)
- Початковий порядок (#8966)
- Перший найменший (#8961)
- Крім найменших і найбільших (#8960)
- *Рамка (#8942)
- Марафон 2 (#8932)
- Усі OK (#8931)
- Видалити цифру (#8843)
- Значення виразу 5 (#8835)
- Різні цифри (#8896)
- Різниця між найбільшим і найменшим (#8959)
- Вивести масив (#8953)
- Модуль числа (#8861)
- Петрик і пиріжки (#8838)
- Значення виразу 2 (#8832)
- Значення змінної 1 (#8825)
- Сума двох цілих 2 (#8805)
- Сума двох цілих (#8804)
- Попереднє число (#8802)
- Наступне число (#8801)
- Hello, Python (#8800)
8. Основи машинного навчання
 Машинне навчання - це галузь штучного інтелекту, яка дозволяє комп'ютерним системам навчатися та покращувати свою роботу на основі досвіду без явного програмування. У цьому розділі ми розглянемо основні концепції та методи машинного навчання.
Машинне навчання - це галузь штучного інтелекту, яка дозволяє комп'ютерним системам навчатися та покращувати свою роботу на основі досвіду без явного програмування. У цьому розділі ми розглянемо основні концепції та методи машинного навчання.
Основні поняття:
- Машинне навчання з учителем - тип навчання, де модель тренується на розмічених даних (є правильні відповіді)
- Машинне навчання без учителя - навчання на нерозмічених даних, де модель сама знаходить закономірності
- Класифікація - задача віднесення об'єкта до однієї з категорій на основі його характеристик
- Регресія - задача передбачення числового значення на основі вхідних даних
У цьому розділі ми розглянемо:
- Основні бібліотеки машинного навчання та їх практичне застосування
- Методи бінарної та багатокласової класифікації
- Лінійну та логістичну регресію
- Поліноміальну регресію та її особливості
- Практичне застосування машинного навчання в іграх
Особлива увага буде приділена практичним проєктам, таким як:
- Створення ШІ для гри "Арканоїд" з прогнозуванням положення м'ячика
- Розробка системи прийняття рішень для руху платформи
- Створення гри "Теніс" з елементами штучного інтелекту
- Програмування системи "Стрілець і ціль" з алгоритмами навчання
8.1. Практична робота: Машинне навчання, Python та миші
Лінійна регресія - метод машинного навчання
Лінійна регресія — це простий і поширений метод машинного навчання, який використовується для прогнозування залежності між змінними. Модель лінійної регресії шукає пряму, що найкраще описує зв'язок між незалежною змінною (вхідними даними) і залежною змінною (результатом або прогнозом).
Формула лінійної регресії
Лінійна регресія моделює залежність між двома змінними за допомогою рівняння прямої:y = kx + b
де:
- y — прогнозоване значення,
- x — незалежна змінна (вхід),
- k — кут нахилу (коефіцієнт або вага),
- b — точка перетину з віссю y (зміщення або інтерсепт).
Мета лінійної регресії — знайти такі значення k і b, щоб лінія найкраще відповідала даним, мінімізуючи помилку між реальними і прогнозованими значеннями.
Приклад
Якщо у вас є дані про продажі автомобілів за роками, лінійна регресія може допомогти спрогнозувати продажі на наступний рік на основі цих даних.
Лінійна регресія є одним із найпростіших алгоритмів для прогнозування, і її часто використовують як базову модель.
Припустимо, ви хочете прогнозувати оцінки студентів на основі кількості годин навчання. Для цього можна використати лінійну регресію для моделювання залежності.
Приклад коду:
import numpy as npfrom sklearn.linear_model import LinearRegression# Дані: роки та кількість студентівyears = np.array([[2017], [2018], [2019], [2020], [2021]])students = np.array([400, 420, 450, 470, 490])
Намалюємо графік за допомогою бібліотеки matplotlib:
import matplotlib.pyplot as pltplt.plot(years, students, marker='o', linestyle='-', color='b')
Параметри функції plot() означають, що ми будуємо графік по точках із масивом years по вісі X, students по вісі Y. Точки мають бути позначені кружечками (o), лінія має бути суцільною (-), а колір має бути синім (b - blue).
Тепер ми можемо створити модель лінійної регресії, яка підбере параметри прямої так, щоб вона максимально точно відповідала нашим даним:
# Створення та навчання моделіmodel = LinearRegression()model.fit(years, students)# Прогноз на 2022 та 2023 рокиpredictions = model.predict(np.array([[2022], [2023]]))print(predictions)Результатом роботи нашої програми буде масив з двох чисел:
array([515., 538.])
що відповідають прогнозній кількості студентів на 2022 та 2023 рік.
Але спочатку, давайте потренуємось працювати із списками.
Завдання №1: Операції зі списками
Дано два списки:
- Список імен студентів:
['Олександр', 'Іван', 'Марія', 'Анна', 'Софія'] - Відповідні оцінки за тест:
[78, 85, 88, 90, 92]
Операції:
- Виведіть ім’я студента, що знаходиться на другій позиції.
- Виведіть оцінку, яку отримала Анна.
- Додайте нове ім’я
"Віктор"і оцінку95до списків. - Виведіть оновлений список студентів та їхні оцінки.
Очікуваний результат:
Іван
90
['Олександр', 'Іван', 'Марія', 'Анна', 'Софія', 'Віктор']
[78, 85, 88, 90, 92, 95]
Завдання №2: Операції з масивами NumPy
Створіть масив з оцінками студентів:
import numpy as npscores = np.array([85, 90, 78, 92, 88, 95, 67, 84, 91, 75])
Операції:
- Обчисліть середнє значення оцінок:
mean_score = np.mean(scores) - Знайдіть мінімальну та максимальну оцінки:
min_score = np.min(scores)max_score = np.max(scores)
Завдання №3: Прогнозуємо розмір мишей за допомогою лінійної регресії
Використовуйте scikit-learn для створення прогнозної моделі розміру мишей на основі їхнього віку.
Дані:
| Вік миші (дні) | Розмір миші (см) | Вага миші (г) |
|---|---|---|
| 5 | 3.1 | 3 |
| 10 | 4.2 | 6 |
| 15 | 5.0 | 12 |
| 20 | 5.8 | 16 |
| 25 | 6.4 | 22 |
| 30 | 7.0 | 28 |
| 42 | 7.5 | 30 |
Використовуючи ці дані, створіть модель лінійної регресії для прогнозування розміру миші на основі її віку.
Код:
import numpy as npfrom sklearn.linear_model import LinearRegression# Даніage = np.array([[5], [10], [15], [20], [25], [30]])size = np.array([3.1, 4.2, 5.0, 5.8, 6.4, 7.0])# Створення моделіmodel = LinearRegression()model.fit(age, size)# Прогноз для 35 днівprediction = model.predict(np.array([[35]]))print(f"Прогнозований розмір миші для 35 днів: {prediction[0]:.2f} см")
Додаткове завдання:
Використовуючи ці дані, створіть модель лінійної регресії для прогнозування розміру миші на основі її ваги, а не віку. Спрогнозуйте, яка має бути довжина миші, у якої вага - 1 кг?
8.2. Лабораторна робота: Класифікація тварин та робота із зображеннями
У цій лабораторній роботі ми навчимося створювати модель машинного навчання для класифікації зображень. Модель допоможе нам навчити компʼютер відрізняти зображення різних тварин, наприклад собак від котів.
Задача класифікації — це один із видів завдань машинного навчання, мета полягає у визначенні, до якого з декількох класів належить об'єкт на основі його характеристик. У такій задачі на вхід подається набір даних, де кожен об'єкт описаний певними ознаками, а вихід — це категорія або клас, до якого належить цей об'єкт. |
|---|
Для початку, нам знадобиться навчитись працювати з файловою системою компʼютера. Робота з файлами у Python є важливою частиною багатьох програм. Python дозволяє відкривати, читати та писати файли, працювати із файловою системою за допомогою вбудованих функцій у пакеті os.
Функція os.listdir()
Ця функція повертає список всіх файлів і директорій у вказаній папці. Це зручно для завантаження наборів зображень чи інших файлів.
import osfiles = os.listdir('шлях/до/папки') # Повертає список файлів у папці
Бібліотека Pillow (PIL)
Модуль Image з бібліотеки PIL надає функції для роботи із зображеннями, такі як читання картинки з файлу, зміна розміру, конвертація в інші формати і багато іншого.
Класифікатор "K сусідів" (K-Nearest Neighbours, KNN)
KNeighborsClassifier — це один із найпростіших і інтуїтивно зрозумілих класифікаторів, що базується на алгоритмі K-Nearest Neighbors (KNN). Він класифікує нові об'єкти на основі близькості до вже класифікованих прикладів у просторі ознак. Ідея методу полягає в тому, що новий об'єкт отримує той клас, до якого належать найближчі до нього сусіди. Кількість сусідів (K) визначається користувачем — це ключовий параметр моделі. Для обчислення "відстані" між об'єктами зазвичай використовують Евклідову відстань, хоча можливі й інші метрики. Перевага KNN — це простота, але він може бути менш ефективним на великих наборах даних або коли потрібно враховувати складні зв'язки між ознаками.
Використаємо платформу Kaggle для цієї роботи
- Увійдіть у свій акаунт Kaggle
- Платформа містить велику кількість наборів даних, для цієї роботи ми візьмемо набір із картинками тварин: https://www.kaggle.com/datasets/antobenedetti/animals
- Натисніть кнопку "New Notebook" на сторінці набору даних Animals
Давайте прочитаємо картинки тварин та перетворимо їх на числа, зрозумілі компʼютеру:
import osfrom PIL import Image# Розмір зображення (ми зменшимо кожну картинку та зробимо їх однакового розміру)image_size = [64, 64]# Функція для завантаження зображень і перетворення їх у масив пікселівdef load_images_from_folder(folder, label): data = [] labels = [] for filename in os.listdir(folder): img_path = os.path.join(folder, filename)
# Прочитаємо кожен файл з папки та завантажимо його як зображення
img = Image.open(img_path).convert('L') # Перетворюємо в градації сірого
img = img.resize(image_size) # Змінюємо розмір
img_array = np.array(img).flatten() # Перетворюємо на список чисел, кожне число - яскра
data.append(img_array)
labels.append(label)
return data, labels
Тепер завантажимо картинки котів та собак. Котів ми закодуємо числом 0, а собак - числом 1.
cats, label_cats = load_images_from_folder('/kaggle/input/animals/animals/train/cat', 0)dogs, label_dogs = load_images_from_folder('/kaggle/input/animals/animals/train/dog', 1)
Тепер створимо класифікатор та виконаємо його тренування на даних які ми зібрали вище:
from sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier(n_neighbors=3)knn.fit(cats + dogs, label_cats + label_dogs)
Після чого ми можемо робити прогноз яка тварина зображена на картинках:
img = Image.open("/kaggle/input/animals/animals/val/dog/dog1.jpg").convert('L') # Відкриваємо нову картинку та перетворюємо її градації сірогоimg = img.resize(image_size) # Змінюємо розмірimg_array = np.array(img).flatten() # Перетворюємо на список чисел - яскравості пікселівr = knn.predict([img_array]) # Робимо прогноз!print("припущення: ", r[0])
припущення: 1
Числом 1 ми закодували собак, одже алгоритм вгадав тварину коректно!
Завдання для самостійної роботи: Класифікація зображень слонів та левів
Мета:
Створити простий класифікатор, який відрізняє зображення слонів від зображень левів. Використовувати K-Nearest Neighbors (KNN) для класифікації зображень, які зберігаються у двох окремих папках: `elephant` та `lion`.
Опис завдання:
1. Завантажити зображення слонів з папки `elephant` та зображення левів з папки `lion`.
2. Використати словники для кодування міток класів (0 для слонів, 1 для левів) та для зворотного декодування результатів.
3. Перетворити зображення на вектори пікселів (в градаціях сірого) і зменшити їх розмір до 64x64 для спрощення.
4. Навчити класифікатор K-Nearest Neighbors (KNN) на тренувальних даних.
- Слони отримують мітку 0.
- Леви отримують мітку 1.
5. Перевірити точність моделі за допомогою класифікації нових зображень, які не були використані при тренуванні (вони знаходяться в папці val)
Додаткові завдання: розпізнавання рукописних чисел
Використовуючи набір даних load_digits, ми будемо працювати із зображеннями цифр (від 0 до 9), представленими у вигляді матриць розміром 8x8.
Кожне зображення — це набір чисел, які описують колір пікселів, а ваше завдання полягає в тому, щоб класифікувати цифру.
До речі, матриця — це прямокутна таблиця чисел, де кожен елемент представляє конкретний піксель зображення. У програмах ми можемо зберігати матриці як двомірні масиви.
# з бібліотеки scikit-learn завантажимо набір данихfrom sklearn.datasets import load_digitsdigits = load_digits()
Як виглядає матриця цифри 3:


Підготовка даних
X = digits.data # Ознаки на яких ми тренуємо штучний інтелект (кольори пікселів)y = digits.target # Мітки (класи зображень)
Давайте подивимось як виглядає число 3 у масиві X - та сама матриця, що ми бачили вище але розгорнута у лінійний масив:
array([ 0., 0., 7., 15., 13., 1., 0., 0., 0., 8., 13., 6., 15., 4., 0., 0., 0., 2., 1., 13., 13., 0., 0., 0., 0., 0., 2., 15., 11., 1., 0., 0., 0., 0., 0., 1., 12., 12., 1., 0., 0., 0., 0., 0., 1., 10., 8., 0., 0., 0., 8., 4., 5., 14., 9., 0., 0., 0., 7., 13., 13., 9., 0., 0.])
Створення навчальної та тестової вибірки
Крок train_test_split дуже важливий у створенні моделей машинного навчання. Він допомагає розділити дані на дві частини: навчальну вибірку (для "тренування" моделі) і тестову вибірку (для перевірки, наскільки добре модель працює).
Це робиться для того, щоб модель не "зазубрила" лише ті дані, на яких навчалась, а могла правильно працювати і з новими даними. Такий підхід допомагає уникнути проблеми, коли модель працює чудово на навчальних даних, але робить багато помилок з іншими.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Тренуємо класифікатор та робимо "передбачення", класифікуємо зображення тестової вибірки
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)knn.fit(X_train, y_train)y_pred = knn.predict(X_test)y_pred
array([9, 8, 6, 7, 1, 4, 4, 3, 1, 9, 0, 2, 6, 8, 7, 6, 5, 0, 9, 1, 0, 9, 9, 1, 9, 0, 6, 3, 1, 5, 7, 0, 1, 1, 3, 4, 8, 2, 0, 7, 8, 8, 6, 4, 1, 9, 8, 9, 4, 1, 1, 3, 5, 4, 2, 7, 4, 0, 3, 3, 8, 3, 0, 1, 4, 1, 3, 3, 8, 3, 9, 6, 6, 9, 8, 7, 6, 2, 6, 4, 3, 9, 7, 6, 3, 2, 9, 5, 2, 6, 0, 0, 3, 8, 7, 7, 1, 3, 1, 5, 6, 4, 3, 9, 0, 7, 3, 6, 0, 2, 5, 1, 9, 6, 9, 4, 8, 8, 6, 1, 2, 4, 1, 3, 5, 7, 3, 6, 8, 1, 8, 0, 0, 7, 2, 3, 1, 5, 3, 4, 2, 1, 1, 3, 2, 2, 7, 5, 3, 1, 2, 3, 9, 7, 2, 6, 7, 0, 7, 1, 4, 7, 3, 0, 7, 2, 9, 2, 7, 5, 9, 4, 7, 1, 8, 0, 6, 3, 1, 1, 5, 3, 3, 6, 4, 3, 0, 9, 8, 8, 1, 7, 1, 7, 8, 8, 4, 8, 9, 1, 0, 4, 3, 8, 2, 8, 0, 1, 1, 3, 4, 0, 0, 1, 3, 5, 0, 7, 1, 6, 7, 6, 7, 0, 6, 9, 6, 5, 4, 6, 6, 5, 9, 8, 8, 1, 8, 7, 9, 9, 7, 7, 9, 4, 6, 7, 4, 0, 3, 5, 3, 4, 8, 1, 3, 6, 5, 4, 8, 0, 3, 3, 4, 7, 1, 7, 3, 8, 7, 3, 8, 7, 9, 8, 5, 6, 8, 7, 9, 3, 6, 7, 9, 9, 8, 7, 0, 8, 7, 1, 0, 1, 0, 7, 2, 1, 4, 8, 0, 8, 7, 4, 4, 7, 0, 5, 7, 5, 4, 5, 2, 4, 9, 5, 7, 6, 0, 6, 6, 5, 3, 2, 5, 4, 4, 9, 1, 3, 4, 5, 9, 6, 6, 0, 8, 5, 8, 9, 3, 9, 0, 0, 3, 2, 2, 6, 9, 1, 1, 3, 2, 5, 3, 0, 7, 8, 1, 5, 8, 7, 3, 3, 3, 0, 0, 9, 1, 9, 3, 8, 0, 2, 6, 9, 6, 1, 4, 8, 5, 1, 5, 5, 5, 7, 2, 4, 1, 8, 1, 5, 8, 6, 0, 1, 5, 0, 3, 4, 5, 8, 6, 9, 6, 4, 8, 1, 4, 1, 1, 2, 0, 9, 2, 2, 3, 4, 8, 7, 5, 7, 5, 3, 8, 3, 6, 8, 4, 5, 7, 2, 2, 4, 6, 4, 0, 9, 3, 5, 5, 5, 4, 3, 6, 1, 3, 2, 5, 4, 2, 4])
- це числа, які зображені на картинках з масиву X_test, як вважає модель.
Виведемо кілька прикладів передбачених значень з їх зображеннями:

Як бачимо, модель успішно розпізнає числа з тестової вибірки.
Додаткові завдання: реалізація алгоритму k-ближчих сусідів (k-NN)
Мета: Навчитись використовувати функції, математичні операції, глибше розібратись із тим як працює метод класифікації k-NN.
Завдання 1: Функція, що рахує відстань між двома точками
Напишіть функцію, яка обчислює Евклідову відстань між двома точками. Кожна точка буде задана у вигляді двох координат (x, y). Формула для обчислення відстані між точками:
\( d = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2} \)
import numpy as np
def distance(x1, y1, x2, y2): return np.sqrt( ... )
Тепер спробуємо, чи працює вона?
pointA = (1, 2)pointB = (4, 6)distance = distance(pointA, pointB)print(f"Відстань між точками A і B: {distance:.2f}")
Завдання 2: Рахуємо відстань до всіх точок
Напишіть функцію, яка для нової точки на графіку знаходить k найближчих сусідів з набору вже відомих точок, використовуючи обчислену відстань.
import matplotlib.pyplot as plt# Даніpoints = [(1, 2), (4, 6), (7, 8), (2, 3), (5, 5)]target = (3, 4)# Розділення координат для графікаx_points, y_points = zip(*points)# Створення графікаplt.scatter(x_points, y_points, color='blue')plt.scatter(*target, color='red', marker='x', s=100)plt.show()
distances = []... # додайте код який рахує відстані від червоного хрестика до кожної із синіх точок, та додає ці відстані у список distances
Завдання 3: Алгоритм пошуку найближчих сусідів
- Впорядкувати відстані до точок від найменшої до найбільшої (можна використати метод `.sort()` списку)
- Знайти найближці k точок-сусідів із них
- Визначити, скільки серед цих k точок належать до класу 1 та до класу 2. В якому класі опиниться найбільше точок, і буде класом до якого ми віднесемо нову точку - це результат роботи нашого алгоритму.
- Реалізувати функцію, яка для нового зображення знаходить k найближчих сусідів серед навчальних даних, обчислюючи відстань до кожного зображення:
def find_k_nearest_neighbors(data, new_point, k): ...
8.3. Проєктна робота
Чекліст для виконання проєкту
- Створити акаунт на GitHub
- Створити персональний сайт за шаблоном на GitHub (шаблон)
- Персоналізувати сайт:
- Переписати сторінки сайту (HTML та CSS)
- Створити окрему HTML-сторінку проєкту та додати посилання на неї з головної сторінки
- На сторінці проєкту:
- Додати опис проєкту
- Перелічити використані технології
- Додати інструкцію користувача
- Створити банер для проєкту за допомогою Canva.com
- Створити проєкт:
- Визначитись із технологією
- Визначитись із темою проєкту
- Зібрати дані для тренування моделі або перевірки роботи програми
- Тренувати або запрограмувати модель штучного інтелекту
- Створити програмний продукт
- Розмістити продукт на сайті
- Тестування
- Розмістити посилання на проєкт на форумі класу
Пітчинг ідеї проєкту
Перед початком роботи над проєктом необхідно представити та обговорити ідею проєкту з викладачем та іншими учнями для отримання зворотного зв'язку та підтвердження її доцільності.
Пітчинг (від англ. pitch - подача) — це коротка презентація ідеї або проєкту потенційним інвесторам, партнерам чи клієнтам. У бізнесі пітчинг використовується для того, щоб за короткий час (зазвичай 3-5 хвилин) переконливо представити свою ідею та отримати підтримку. Це важлива навичка для стартаперів та підприємців. У нашому випадку пітчинг допоможе вам структуровано представити ідею вашого проєкту, отримати зворотній зв'язок від викладача та однокласників, а також навчитися презентувати свої ідеї професійно.
Структура презентації для пітчингу
- Слайд 1. Обкладинка
- Назва проєкту
- Логотип або банер
- Імена учасників команди
- Слайд 2. Проблема або потреба
- Яку проблему ви вирішуєте?
- Слайд 3. Ідея і рішення
- Ваша ідея: що саме ви пропонуєте.
- Як ваш проєкт вирішує проблему
- Слайд 4. Обрані інструменти і технології
- Список інструментів, які ви використовуєте (з іконками або короткими поясненнями).
- Пояснити, чому саме ці інструменти?
- Слайд 5. Сторінка проєкту на персональному сайті
- Скріншот або демонстрація сторінки сайту.
- Слайд 6. Робота з даними
- Які дані потрібні?
- Як ви плануєте їх збирати і використовувати?
Після роботи над проєктом необхідно буде представити презентацію, сторінку проєкту на персональному сайті та продемонструвати роботу програми.
Структура презентації для захисту проєкту
- Слайд 1. Обкладинка
- Назва проєкту
- Логотип або банер
- Імена учасників команди
- Дата захисту
- Слайд 2. Проблема або потреба
- Яку проблему ви вирішуєте?
- Слайд 3. Ідея і рішення
- Ваша ідея: що саме ви пропонуєте.
- Як ваш проєкт вирішує проблему
- Які є аналоги?
- Слайд 4. Компоненти проєкту (схемою)
- Натреновані чи використані моделі ШІ: які інструменти використані?
- Які частини програмного продукту створені, які мови програмування використані.
- Слайд 5. Штучний інтелект
- Теоретичні відомості про модель, яка була використана та як вона працює.
- Слайд 6. Робота з даними
- Які дані були зібрані (показати приклади).
- Якість моделі (у цифрах).
- Слайд 7. Демонстрація результату
- Демонстрації роботи
- Посилання на працюючий проєкт
- Слайд 8. Висновки і результати
- Що вдалося реалізувати
- Що не встигли, але планували
- Основні досягнення
Що необхідно додати до захисту в 11 класі: Етична складова, feature matrix аналогів, розрахунок якості моделей
9. Збір даних
У сучасному світі дані стали одним із найцінніших ресурсів. Правильний збір, обробка та аналіз даних є ключовими елементами для прийняття обґрунтованих рішень у різних сферах діяльності.
Основні поняття:
- Збір даних - це процес збирання та вимірювання інформації за визначеними змінними, який дозволяє відповісти на актуальні запитання та оцінити результати.
- Data Mining (добування даних) - це процес виявлення закономірностей у великих наборах даних з використанням методів машинного навчання, статистики та систем баз даних.
- Feature Engineering (конструювання ознак) - це процес створення нових ознак на основі існуючих даних для покращення ефективності моделей машинного навчання.
У цій темі ми розглянемо:
- Етичні аспекти збору та використання даних
- Інструменти для збору та обробки даних
- Методи оцінки якості даних
- Способи візуалізації даних
- Техніки добування даних (Data Mining)
- Методи конструювання ознак (Feature Engineering)
Буде приділена практичній роботі з порталом відкритих даних України https://data.gov.ua. Ви навчитеся не лише збирати дані, але й оцінювати їх якість та створювати нові ознаки для покращення аналітичних моделей.
9.1. Orange Data Mining
Orange - це простий, але потужний інструмент для аналізу даних та машинного навчання з відкритим кодом. Він надає візуальний інтерфейс для аналізу даних, що робить його особливо зручним для початківців та освітніх цілей. За допомогою Orange можна виконувати різноманітні завдання: від базової візуалізації даних до складних алгоритмів машинного навчання.
Щоб встановити Orange на свій комп'ютер:
- Перейдіть на офіційний сайт Orange: https://orangedatamining.com/download/
- Оберіть версію для вашої операційної системи
- Завантажте інсталяційний файл
- Запустіть завантажений інсталятор та дотримуйтесь інструкцій з установки
Після завершення установки ви зможете знайти Orange у меню програм вашого комп'ютера та запустити Orange Canvas - графічний інтерфейс програми, де можна створювати робочі процеси аналізу даних, перетягуючи та з'єднуючи різні компоненти.
Офіційний сайт проекту: https://orangedatamining.com/
9.2. Розвідувальний аналіз
Розвідувальний аналіз даних (англ. Exploratory data analysis) - це перший важливий крок у роботі з даними. На цьому етапі ми вивчаємо основні характеристики наших даних, щоб краще зрозуміти їх природу. Це як перше знайомство з новим набором інформації - ми розглядаємо його з різних сторін, шукаємо цікаві закономірності та незвичні випадки. Для цього використовуємо різні інструменти візуалізації - графіки, діаграми, гістограми, а також статистичні методи.
Почнемо з найпростішого - подивимось на самі дані в табличному вигляді. У програмі Orange для цього є зручний інструмент під назвою Data Table.
Наступний крок - дізнатися більше про кожну колонку даних за допомогою статистичних показників. Для цього в Orange використовуємо інструмент Feature Statistics.
Дуже важливо також зрозуміти, як різні показники пов'язані між собою. Це можна побачити за допомогою інструменту Correlation в Orange.
Кореляція показує, наскільки сильно пов'язані між собою дві змінні. Якщо кореляція близька до 1 - змінні мають сильний прямий зв'язок, якщо до 0 - зв'язку практично немає.
Розглянемо простий приклад: уявіть, що ми аналізуємо дані про продажі морозива протягом року. Якщо порівняти продажі з температурою повітря, ми побачимо сильну кореляцію - чим тепліше надворі, тим більше купують морозива. А от якщо порівняти продажі морозива з, наприклад, цінами на бензин - кореляція буде близька до нуля, бо ці показники ніяк не пов'язані між собою.
Orange також пропонує зручні інструменти для візуалізації даних. Наприклад, Scatter plot (точкова діаграма) допомагає наочно побачити зв'язок між двома показниками, а Box plot (діаграма розмаху) показує, як розподілені значення в наших даних. Ці візуалізації роблять аналіз більш зрозумілим та інтуїтивним.
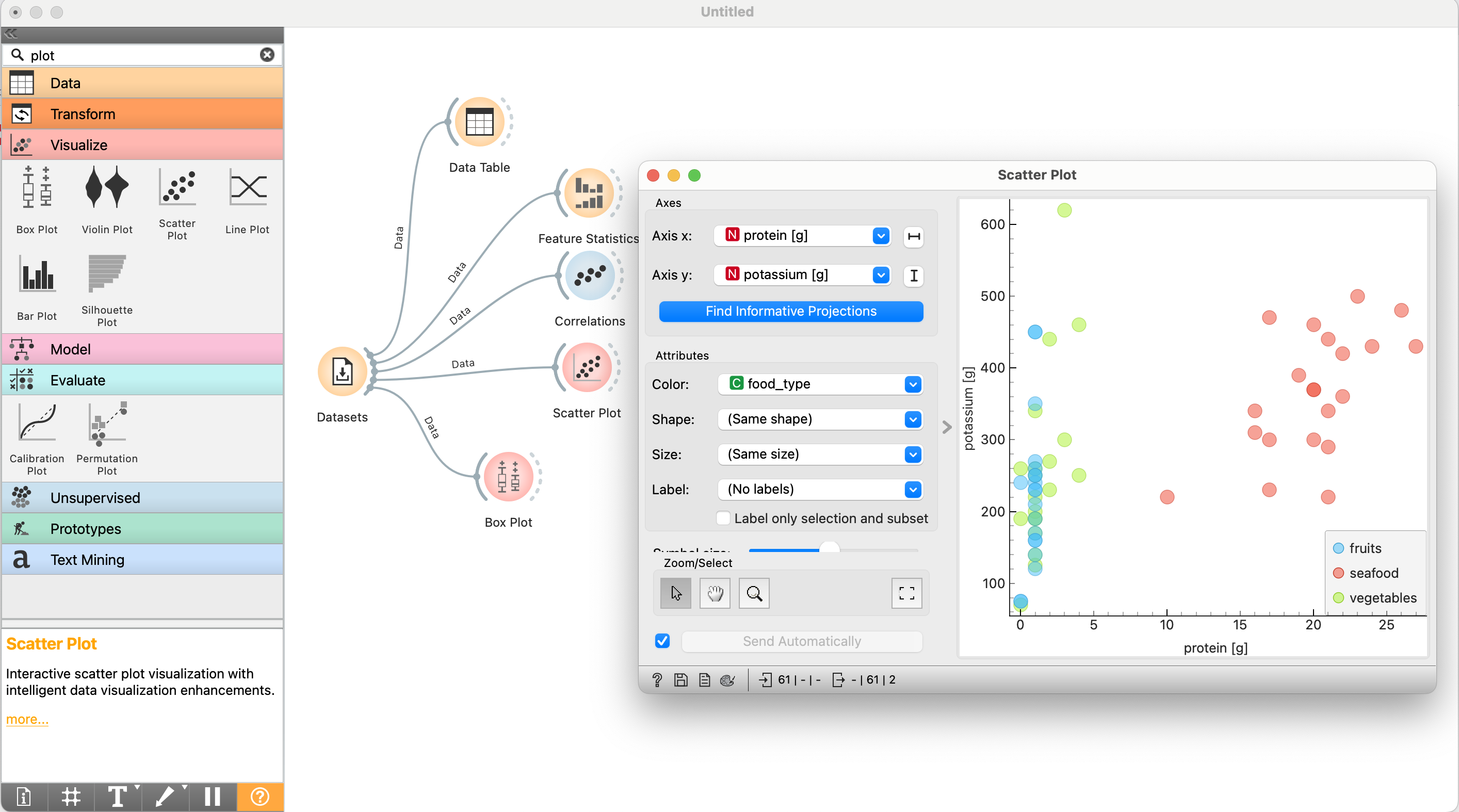
10. Нейронні мережі
Нейронні мережі - це потужний інструмент машинного навчання, що імітує роботу людського мозку. Подібно до того, як наш мозок складається з мільярдів взаємопов'язаних нейронів, штучні нейронні мережі побудовані з математичних моделей нейронів, з'єднаних між собою.
У цьому розділі ми:
- познайомимося з основними компонентами нейронних мереж
- дослідимо, як працює найпростіша модель нейрона - персептрон
- вивчимо ключові концепції: функції активації та функції втрат
- розберемо алгоритм зворотного поширення помилки
- навчимося створювати та тренувати прості нейронні мережі
Нейронні мережі знайшли широке застосування у різних сферах: від розпізнавання образів та мови до медичної діагностики та прогнозування погоди. Їх унікальна здатність до навчання та апроксимації складних нелінійних залежностей робить їх незамінними у вирішенні багатьох практичних задач.
На практиці ми реалізуємо власну нейронну мережу для класифікації квітів ірисів - класичної задачі машинного навчання. Це допоможе нам краще зрозуміти принципи роботи нейронних мереж та отримати практичний досвід їх застосування.
10.1. Персептрон
Персептрон був розроблений Френком Розенблаттом у 1957 році в Корнельській авіаційній лабораторії. Це була перша штучна нейронна мережа, реалізована у вигляді комп'ютерної програми, що могла навчатися розпізнавати прості візуальні патерни. Назва "персептрон" походить від слова "perception" (сприйняття), оскільки модель була натхненна біологічними механізмами обробки візуальної інформації. Ця модель заклала фундамент для розвитку сучасних нейронних мереж та глибокого навчання.
Аналогія з біологічним нейрономПерсептрон був створений за аналогією з біологічним нейроном і має схожу структуру:
- Дендрити - в біологічному нейроні це відростки, що приймають вхідні сигнали від інших нейронів. У персептроні цю роль виконують вхідні зв'язки (входи), через які надходять вхідні дані.
- Тіло клітини (сома) - у біологічному нейроні тут відбувається обробка сигналів. У персептроні це відповідає зваженому сумуванню всіх вхідних сигналів.
- Аксон - у біологічному нейроні це довгий відросток, що передає вихідний сигнал іншим нейронам. У персептроні це вихідний сигнал після функції активації.
- Синапси - у біологічному нейроні це місця з'єднання між нейронами, що мають різну силу зв'язку. У персептроні це ваги зв'язків між входами та нейроном.
Функція активації персептрона працює у два етапи:
- Зважене сумування - кожен вхідний сигнал множиться на відповідну вагу зв'язку, після чого всі добутки додаються. Це можна записати як: sum = x₁w₁ + x₂w₂ + ... + xₙwₙ, де x - вхідні сигнали, а w - ваги зв'язків.
- Порогова функція - отримана сума порівнюється з пороговим значенням. Якщо сума перевищує поріг, нейрон активується (видає 1), інакше залишається неактивним (видає 0). Це забезпечує здатність персептрона приймати рішення на основі вхідних даних.
Навчання персептрона полягає в підборі оптимальних ваг зв'язків, щоб він правильно класифікував вхідні дані. Процес навчання відбувається так:
- Ініціалізація - спочатку ваги встановлюються випадковим чином (зазвичай малі значення)
- Подача навчального прикладу - на вхід подається навчальний приклад, для якого відомий правильний результат
- Обчислення виходу - персептрон обчислює свій вихід для поданого прикладу
- Порівняння з правильною відповіддю - якщо вихід не співпадає з очікуваним результатом, відбувається корекція ваг
- Корекція ваг - ваги змінюються за формулою:
w_new = w_old + η(d - y)x
де:- w_new - нове значення ваги
- w_old - старе значення ваги
- η (ета) - швидкість навчання (маленьке додатне число)
- d - правильний (бажаний) вихід
- y - фактичний вихід персептрона
- x - значення входу
- Повторення - кроки 2-5 повторюються для всіх навчальних прикладів, доки персептрон не почне правильно класифікувати всі приклади або не буде досягнуто максимальної кількості ітерацій
Важливо розуміти, що персептрон може навчитися розділяти тільки лінійно роздільні класи даних. Це означає, що якщо дані можна розділити прямою лінією (у двовимірному просторі) або гіперплощиною (у багатовимірному просторі), персептрон зможе їх класифікувати. Для складніших задач потрібні більш складні нейронні мережі.
Демонстрація роботи персептронаhttps://perceptrondemo.com/ (автоматичний переклад українською добре працює).
11. Основи обробки природної мови
 Обробка природної мови (Natural Language Processing, NLP) - це галузь штучного інтелекту, що займається взаємодією між комп'ютерами та людською мовою. Це складна та захоплююча область, яка дозволяє комп'ютерам "розуміти", аналізувати та генерувати людську мову.
Обробка природної мови (Natural Language Processing, NLP) - це галузь штучного інтелекту, що займається взаємодією між комп'ютерами та людською мовою. Це складна та захоплююча область, яка дозволяє комп'ютерам "розуміти", аналізувати та генерувати людську мову.
У цьому розділі ми:
- вивчимо основні концепції математичної лінгвістики, включаючи закон Ціпфа
- познайомимося з базовими методами обробки тексту: токенізацією та n-грамами
- освоїмо різні способи кодування тексту (one-hot encoding, bag of words)
- навчимося добувати семантичні ознаки з тексту
- розглянемо практичні застосування NLP: аналіз настрою та класифікацію текстів
Сьогодні технології NLP використовуються повсюдно: від пошукових систем та перекладачів до голосових помічників та чат-ботів. Розуміння принципів роботи з текстовими даними є важливою навичкою для сучасного спеціаліста з штучного інтелекту.
На практиці ми створимо програму для аналізу відгуків до фільмів, де застосуємо вивчені методи для визначення емоційного забарвлення тексту. Це дозволить нам побачити, як теоретичні знання застосовуються у реальних задачах обробки природної мови.
11.1. Класифікація текстів
Orange3
Confusion matrix - якість моделі
Prec / Recall
12. Природна мова та генеративний ШІ
Генеративний штучний інтелект - це новий етап у розвитку технологій обробки природної мови, який дозволяє не лише аналізувати, але й створювати осмислений текстовий контент. У цьому розділі ми заглибимось у сучасні методи роботи з текстом та розглянемо, як комп'ютери "розуміють" значення слів та речень.
У цьому розділі ми:
- дослідимо методи представлення тексту через хмари слів та різні види кодування
- вивчимо алгоритм Word2Vec для виявлення семантичної подібності між словами
- розберемо концепцію контекстуальних вкладань слів (contextual embeddings)
- познайомимося з принципами роботи великих лінгвістичних моделей
- розглянемо практичні застосування: підсумовування тексту та машинний переклад
Сучасні генеративні моделі здатні створювати тексти, що важко відрізнити від написаних людиною, перекладати між мовами та створювати короткі реферати довгих документів. Розуміння принципів їх роботи є ключовим для розробки ефективних систем обробки тексту.
На практиці ми створимо систему перевірки на плагіат, використовуючи векторні представлення тексту, та розробимо просту модель для передбачення наступного слова в реченні. Це допоможе краще зрозуміти принципи роботи сучасних мовних моделей.
12.1. Моделювання простої мовної моделі
Мовні моделі - це клас алгоритмів штучного інтелекту, які вміють працювати з текстом. Їх головне завдання - передбачати, яке слово найімовірніше з'явиться далі в тексті, враховуючи попередні слова. Хоча сучасні мовні моделі (як-от GPT чи BERT) побудовані на складних нейронних мережах, ми можемо зрозуміти основний принцип їх роботи на простішому прикладі.
Практична робота: Створення простої мовної моделі
Мета: Навчитися створювати базову мовну модель, яка передбачає наступне слово на основі двох попередніх слів.
Хід роботи:
- Підготовка даних:
- Візьміть будь-який текст для навчання моделі
- Розбийте його на групи по три слова, де перші два будуть контекстом, а третє - тим, що модель має передбачити
- Створення моделі в Orange:
- Додайте блок Select Columns
- Виберіть колонку context як ознаку (Feature)
- Виберіть колонку next_token як цільову змінну (Target)
- Використайте Bag of Words або TF-IDF для перетворення слів у числа
- Додайте модель машинного навчання (Logistic Regression або Naive Bayes)
- Тестування моделі:
- Використайте блок Test & Score для оцінки якості моделі
- Перевірте роботу моделі на нових прикладах через блок Predict
Висновок: Створена модель вчиться знаходити закономірності в тексті - які слова найчастіше йдуть після певних комбінацій інших слів. Наприклад, якщо в навчальних даних після слів "червона" та "машина" часто зустрічається слово "їде", модель буде пропонувати саме це слово. Цей простий принцип лежить в основі сучасних чат-ботів та систем обробки тексту, хоча вони використовують значно складніші алгоритми.
13. Глибинне навчання
Глибинне навчання (Deep Learning) - це передовий напрямок машинного навчання, що базується на використанні багатошарових нейронних мереж. На відміну від традиційних нейронних мереж, глибинні моделі здатні автоматично виявляти складні ієрархічні ознаки в даних, що робить їх особливо ефективними для вирішення складних задач.
У цьому розділі ми:
- вивчимо основні концепції глибинного навчання та його відмінності від класичних нейронних мереж
- познайомимося з бібліотекою PyTorch для створення глибинних нейронних мереж
- розберемо принципи роботи конволюційних нейронних мереж
- дослідимо, як відбувається автоматичне виділення ознак на різних шарах мережі
- розглянемо практичні застосування в комп'ютерному зорі та розпізнаванні зображень
Сьогодні глибинне навчання є основою багатьох сучасних технологій: від систем розпізнавання обличчя та мови до автономних транспортних засобів та медичної діагностики. Розуміння принципів роботи глибинних нейронних мереж відкриває широкі можливості для створення інтелектуальних систем нового покоління.
На практиці ми створимо систему комп'ютерного зору, яка зможе розпізнавати та класифікувати об'єкти в реальному часі за допомогою камери. Це дозволить нам побачити, як теоретичні знання про глибинне навчання застосовуються у реальних проєктах.
14. Проєктна діяльність
У цьому розділі ми застосуємо отримані знання для створення реального проєкту - автоматизованої системи контролю відвідування занять з використанням технології розпізнавання облич. Це дозволить нам пройти всі етапи розробки системи штучного інтелекту: від збору даних до розгортання готового рішення.
У цьому розділі ми:
- спроєктуємо архітектуру системи розпізнавання облич
- навчимося правильно збирати та готувати дані для навчання моделі
- освоїмо процес тренування та оптимізації моделей машинного навчання
- розберемо методи оцінки якості та точності створених моделей
- отримаємо досвід презентації технічного проєкту
Проєкт дозволить застосувати на практиці різні аспекти машинного навчання: від попередньої обробки даних до тонкого налаштування моделей. Особлива увага буде приділена оцінці якості роботи системи та її оптимізації для досягнення максимальної точності розпізнавання.
В рамках проєкту ми будемо працювати в командах, змагаючись у створенні найбільш ефективного рішення. Це допоможе краще зрозуміти важливість кожного етапу розробки та навчитися приймати обґрунтовані технічні рішення. Завершиться розділ презентацією проєктів, де кожна команда представить своє рішення та поділиться отриманим досвідом.