Основи інженерії штучного інтелекту 10-11 класи
Цей документ містить навчальні матеріали для учнів та вчителів курсу «Основи інженерії штучного інтелекту». Навчальна програма курсу за вибором "Основи інженерії штучного інтелекту" Автори: Рибак О.С., Радер Р.І. Протокол №7 від 19.08.2024. Зареєстровано у каталозі надання грифів навчальних матеріалів та навчальних програм № 4.0164-2024 (Текст програми (pdf))
8. Основи машинного навчання
8.2. Лабораторна робота: Класифікація тварин та робота із зображеннями
У цій лабораторній роботі ми навчимося створювати модель машинного навчання для класифікації зображень. Модель допоможе нам навчити компʼютер відрізняти зображення різних тварин, наприклад собак від котів.
Задача класифікації — це один із видів завдань машинного навчання, мета полягає у визначенні, до якого з декількох класів належить об'єкт на основі його характеристик. У такій задачі на вхід подається набір даних, де кожен об'єкт описаний певними ознаками, а вихід — це категорія або клас, до якого належить цей об'єкт. |
|---|
Для початку, нам знадобиться навчитись працювати з файловою системою компʼютера. Робота з файлами у Python є важливою частиною багатьох програм. Python дозволяє відкривати, читати та писати файли, працювати із файловою системою за допомогою вбудованих функцій у пакеті os.
Функція os.listdir()
Ця функція повертає список всіх файлів і директорій у вказаній папці. Це зручно для завантаження наборів зображень чи інших файлів.
import osfiles = os.listdir('шлях/до/папки') # Повертає список файлів у папці
Бібліотека Pillow (PIL)
Модуль Image з бібліотеки PIL надає функції для роботи із зображеннями, такі як читання картинки з файлу, зміна розміру, конвертація в інші формати і багато іншого.
Класифікатор "K сусідів" (K-Nearest Neighbours, KNN)
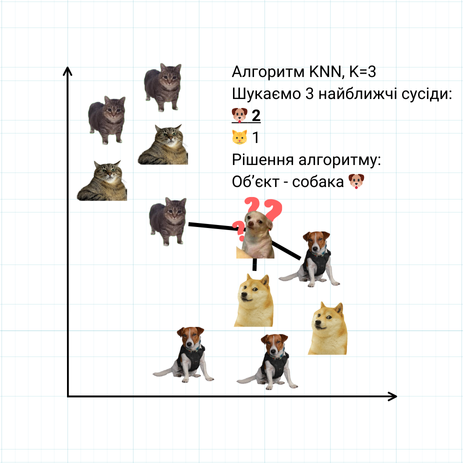
KNeighborsClassifier — це один із найпростіших і інтуїтивно зрозумілих класифікаторів, що базується на алгоритмі K-Nearest Neighbors (KNN). Він класифікує нові об'єкти на основі близькості до вже класифікованих прикладів у просторі ознак. Ідея методу полягає в тому, що новий об'єкт отримує той клас, до якого належать найближчі до нього сусіди. Кількість сусідів (K) визначається користувачем — це ключовий параметр моделі. Для обчислення "відстані" між об'єктами зазвичай використовують Евклідову відстань, хоча можливі й інші метрики. Перевага KNN — це простота, але він може бути менш ефективним на великих наборах даних або коли потрібно враховувати складні зв'язки між ознаками.
Використаємо платформу Kaggle для цієї роботи
- Увійдіть у свій акаунт Kaggle
- Платформа містить велику кількість наборів даних, для цієї роботи ми візьмемо набір із картинками тварин: https://www.kaggle.com/datasets/antobenedetti/animals
- Натисніть кнопку "New Notebook" на сторінці набору даних Animals
Давайте прочитаємо картинки тварин та перетворимо їх на числа, зрозумілі компʼютеру:
import osfrom PIL import Image# Розмір зображення (ми зменшимо кожну картинку та зробимо їх однакового розміру)image_size = [64, 64]# Функція для завантаження зображень і перетворення їх у масив пікселівdef load_images_from_folder(folder, label): data = [] labels = [] for filename in os.listdir(folder): img_path = os.path.join(folder, filename)
# Прочитаємо кожен файл з папки та завантажимо його як зображення
img = Image.open(img_path).convert('L') # Перетворюємо в градації сірого
img = img.resize(image_size) # Змінюємо розмір
img_array = np.array(img).flatten() # Перетворюємо на список чисел, кожне число - яскра
data.append(img_array)
labels.append(label)
return data, labels
Тепер завантажимо картинки котів та собак. Котів ми закодуємо числом 0, а собак - числом 1.
cats, label_cats = load_images_from_folder('/kaggle/input/animals/animals/train/cat', 0)dogs, label_dogs = load_images_from_folder('/kaggle/input/animals/animals/train/dog', 1)
Тепер створимо класифікатор та виконаємо його тренування на даних які ми зібрали вище:
from sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier(n_neighbors=3)knn.fit(cats + dogs, label_cats + label_dogs)
Після чого ми можемо робити прогноз яка тварина зображена на картинках:
img = Image.open("/kaggle/input/animals/animals/val/dog/dog1.jpg").convert('L') # Відкриваємо нову картинку та перетворюємо її градації сірогоimg = img.resize(image_size) # Змінюємо розмірimg_array = np.array(img).flatten() # Перетворюємо на список чисел - яскравості пікселівr = knn.predict([img_array]) # Робимо прогноз!print("припущення: ", r[0])
припущення: 1
Числом 1 ми закодували собак, одже алгоритм вгадав тварину коректно!
Завдання для самостійної роботи: Класифікація зображень слонів та левів
Мета:
Створити простий класифікатор, який відрізняє зображення слонів від зображень левів. Використовувати K-Nearest Neighbors (KNN) для класифікації зображень, які зберігаються у двох окремих папках: `elephant` та `lion`.
Опис завдання:
1. Завантажити зображення слонів з папки `elephant` та зображення левів з папки `lion`.
2. Використати словники для кодування міток класів (0 для слонів, 1 для левів) та для зворотного декодування результатів.
3. Перетворити зображення на вектори пікселів (в градаціях сірого) і зменшити їх розмір до 64x64 для спрощення.
4. Навчити класифікатор K-Nearest Neighbors (KNN) на тренувальних даних.
- Слони отримують мітку 0.
- Леви отримують мітку 1.
5. Перевірити точність моделі за допомогою класифікації нових зображень, які не були використані при тренуванні (вони знаходяться в папці val)
Додаткові завдання: розпізнавання рукописних чисел
Використовуючи набір даних load_digits, ми будемо працювати із зображеннями цифр (від 0 до 9), представленими у вигляді матриць розміром 8x8.
Кожне зображення — це набір чисел, які описують колір пікселів, а ваше завдання полягає в тому, щоб класифікувати цифру.
До речі, матриця — це прямокутна таблиця чисел, де кожен елемент представляє конкретний піксель зображення. У програмах ми можемо зберігати матриці як двомірні масиви.
# з бібліотеки scikit-learn завантажимо набір данихfrom sklearn.datasets import load_digitsdigits = load_digits()
Як виглядає матриця цифри 3:


Підготовка даних
X = digits.data # Ознаки на яких ми тренуємо штучний інтелект (кольори пікселів)y = digits.target # Мітки (класи зображень)
Давайте подивимось як виглядає число 3 у масиві X - та сама матриця, що ми бачили вище але розгорнута у лінійний масив:
array([ 0., 0., 7., 15., 13., 1., 0., 0., 0., 8., 13., 6., 15., 4., 0., 0., 0., 2., 1., 13., 13., 0., 0., 0., 0., 0., 2., 15., 11., 1., 0., 0., 0., 0., 0., 1., 12., 12., 1., 0., 0., 0., 0., 0., 1., 10., 8., 0., 0., 0., 8., 4., 5., 14., 9., 0., 0., 0., 7., 13., 13., 9., 0., 0.])
Створення навчальної та тестової вибірки
Крок train_test_split дуже важливий у створенні моделей машинного навчання. Він допомагає розділити дані на дві частини: навчальну вибірку (для "тренування" моделі) і тестову вибірку (для перевірки, наскільки добре модель працює).
Це робиться для того, щоб модель не "зазубрила" лише ті дані, на яких навчалась, а могла правильно працювати і з новими даними. Такий підхід допомагає уникнути проблеми, коли модель працює чудово на навчальних даних, але робить багато помилок з іншими.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Тренуємо класифікатор та робимо "передбачення", класифікуємо зображення тестової вибірки
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)knn.fit(X_train, y_train)y_pred = knn.predict(X_test)y_pred
array([9, 8, 6, 7, 1, 4, 4, 3, 1, 9, 0, 2, 6, 8, 7, 6, 5, 0, 9, 1, 0, 9, 9, 1, 9, 0, 6, 3, 1, 5, 7, 0, 1, 1, 3, 4, 8, 2, 0, 7, 8, 8, 6, 4, 1, 9, 8, 9, 4, 1, 1, 3, 5, 4, 2, 7, 4, 0, 3, 3, 8, 3, 0, 1, 4, 1, 3, 3, 8, 3, 9, 6, 6, 9, 8, 7, 6, 2, 6, 4, 3, 9, 7, 6, 3, 2, 9, 5, 2, 6, 0, 0, 3, 8, 7, 7, 1, 3, 1, 5, 6, 4, 3, 9, 0, 7, 3, 6, 0, 2, 5, 1, 9, 6, 9, 4, 8, 8, 6, 1, 2, 4, 1, 3, 5, 7, 3, 6, 8, 1, 8, 0, 0, 7, 2, 3, 1, 5, 3, 4, 2, 1, 1, 3, 2, 2, 7, 5, 3, 1, 2, 3, 9, 7, 2, 6, 7, 0, 7, 1, 4, 7, 3, 0, 7, 2, 9, 2, 7, 5, 9, 4, 7, 1, 8, 0, 6, 3, 1, 1, 5, 3, 3, 6, 4, 3, 0, 9, 8, 8, 1, 7, 1, 7, 8, 8, 4, 8, 9, 1, 0, 4, 3, 8, 2, 8, 0, 1, 1, 3, 4, 0, 0, 1, 3, 5, 0, 7, 1, 6, 7, 6, 7, 0, 6, 9, 6, 5, 4, 6, 6, 5, 9, 8, 8, 1, 8, 7, 9, 9, 7, 7, 9, 4, 6, 7, 4, 0, 3, 5, 3, 4, 8, 1, 3, 6, 5, 4, 8, 0, 3, 3, 4, 7, 1, 7, 3, 8, 7, 3, 8, 7, 9, 8, 5, 6, 8, 7, 9, 3, 6, 7, 9, 9, 8, 7, 0, 8, 7, 1, 0, 1, 0, 7, 2, 1, 4, 8, 0, 8, 7, 4, 4, 7, 0, 5, 7, 5, 4, 5, 2, 4, 9, 5, 7, 6, 0, 6, 6, 5, 3, 2, 5, 4, 4, 9, 1, 3, 4, 5, 9, 6, 6, 0, 8, 5, 8, 9, 3, 9, 0, 0, 3, 2, 2, 6, 9, 1, 1, 3, 2, 5, 3, 0, 7, 8, 1, 5, 8, 7, 3, 3, 3, 0, 0, 9, 1, 9, 3, 8, 0, 2, 6, 9, 6, 1, 4, 8, 5, 1, 5, 5, 5, 7, 2, 4, 1, 8, 1, 5, 8, 6, 0, 1, 5, 0, 3, 4, 5, 8, 6, 9, 6, 4, 8, 1, 4, 1, 1, 2, 0, 9, 2, 2, 3, 4, 8, 7, 5, 7, 5, 3, 8, 3, 6, 8, 4, 5, 7, 2, 2, 4, 6, 4, 0, 9, 3, 5, 5, 5, 4, 3, 6, 1, 3, 2, 5, 4, 2, 4])
- це числа, які зображені на картинках з масиву X_test, як вважає модель.
Виведемо кілька прикладів передбачених значень з їх зображеннями:

Як бачимо, модель успішно розпізнає числа з тестової вибірки.
Додаткові завдання: реалізація алгоритму k-ближчих сусідів (k-NN)
Мета: Навчитись використовувати функції, математичні операції, глибше розібратись із тим як працює метод класифікації k-NN.
Завдання 1: Функція, що рахує відстань між двома точками
Напишіть функцію, яка обчислює Евклідову відстань між двома точками. Кожна точка буде задана у вигляді двох координат (x, y). Формула для обчислення відстані між точками:
\( d = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2} \)
import numpy as np
def distance(x1, y1, x2, y2): return np.sqrt( ... )
Тепер спробуємо, чи працює вона?
pointA = (1, 2)pointB = (4, 6)distance = distance(pointA, pointB)print(f"Відстань між точками A і B: {distance:.2f}")
Завдання 2: Рахуємо відстань до всіх точок
Напишіть функцію, яка для нової точки на графіку знаходить k найближчих сусідів з набору вже відомих точок, використовуючи обчислену відстань.
import matplotlib.pyplot as plt# Даніpoints = [(1, 2), (4, 6), (7, 8), (2, 3), (5, 5)]target = (3, 4)# Розділення координат для графікаx_points, y_points = zip(*points)# Створення графікаplt.scatter(x_points, y_points, color='blue')plt.scatter(*target, color='red', marker='x', s=100)plt.show()
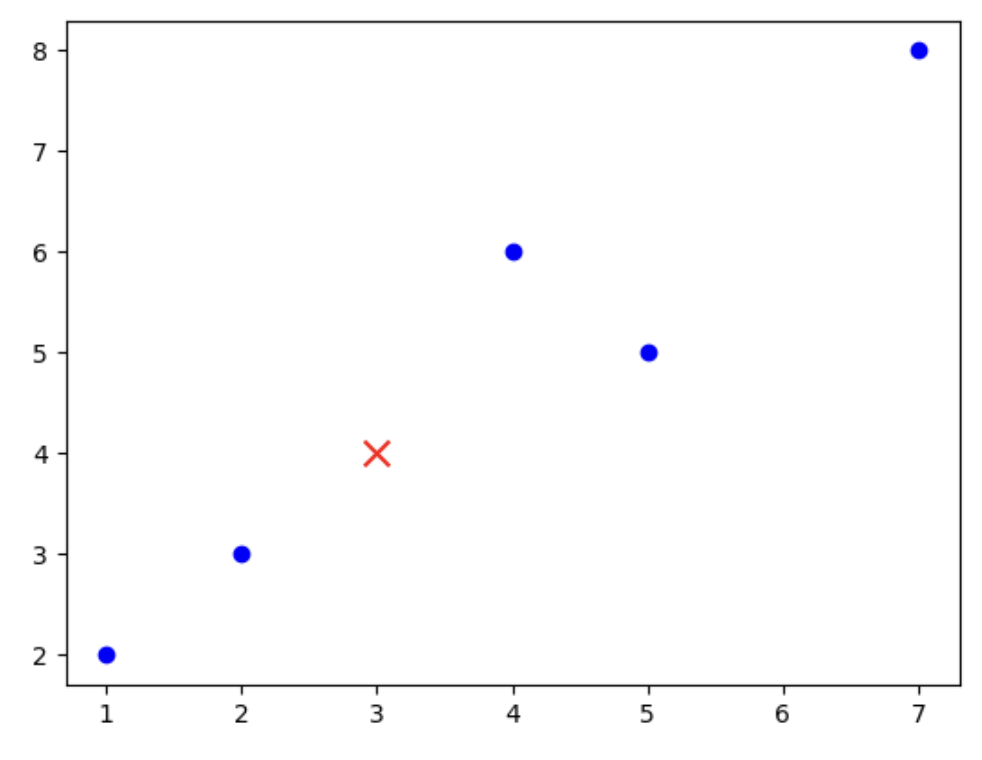
distances = []... # додайте код який рахує відстані від червоного хрестика до кожної із синіх точок, та додає ці відстані у список distances
Завдання 3: Алгоритм пошуку найближчих сусідів
- Впорядкувати відстані до точок від найменшої до найбільшої (можна використати метод `.sort()` списку)
- Знайти найближці k точок-сусідів із них
- Визначити, скільки серед цих k точок належать до класу 1 та до класу 2. В якому класі опиниться найбільше точок, і буде класом до якого ми віднесемо нову точку - це результат роботи нашого алгоритму.
- Реалізувати функцію, яка для нового зображення знаходить k найближчих сусідів серед навчальних даних, обчислюючи відстань до кожного зображення:
def find_k_nearest_neighbors(data, new_point, k): ...