Основи інженерії штучного інтелекту 10-11 класи
Цей документ містить навчальні матеріали для учнів та вчителів курсу «Основи інженерії штучного інтелекту». Навчальна програма курсу за вибором "Основи інженерії штучного інтелекту" Автори: Рибак О.С., Радер Р.І. Протокол №7 від 19.08.2024. Зареєстровано у каталозі надання грифів навчальних матеріалів та навчальних програм № 4.0164-2024 (Текст програми (pdf))
3. Програмування для ШI
3.5. Бібліотека Pandas. Робота із наборами даних. Практична робота із прогнозування якості повітря.
Забруднення повітря є однією з найбільших екологічних проблем сучасності, що впливає як на здоров’я, так і на довкілля. Особливо небезпечними є дрібнодисперсні частинки PM2.5 (частинки до 2.5 мікронів), які можуть проникати в легені й викликати серйозні захворювання дихальної та серцево-судинної систем. У Києві рівень PM2.5 часто зростає через смог, торфяні пожежі, а також вплив глобальних явищ, таких як пилові бурі з Сахари.
У цій практичній роботі ми проведемо аналіз якості повітря у м. Києві, використовуючи дані SaveEcoBot з станції №16788, розташованої у Дніпровському районі. Особливу увагу приділимо рівню PM2.5 за квітень 2024 року, коли на рівень забруднення могли вплинути як місцеві фактори, так і пилові бурі, зафіксовані метеорологами в інших регіонах України.
Мета: створити прогнозну модель для визначення рівня PM2.5, враховуючи історичні дані. Для цього ми використаємо інструменти машинного навчання, познайомимось із поняттям лінійної регресії та базовим методам аналізу часових рядів.
Набір даних з яким ми будемо працювати ви можете знайти за адресою https://www.kaggle.com/competitions/kyiv-air-quality-ai-lab-1 , або завантажити CSV файл напряму із сайту SaveEcoBot тієї станції яка знаходиться бліжче до вас (натисніть на посилання "Завантажити дані у форматі CSV").
У цій практичній роботі ми будемо використовувати бібліотеку Pandas для зручного читання, обробки та аналізу табличних даних. Вона допоможе нам очистити дані, виконати попередній аналіз і підготувати їх для побудови прогнозної моделі. Щоб працювати з Pandas, спочатку необхідно імпортувати її у свій проєкт, використовуючи команду import pandas as pd. Після чого можна використати функцію read_csv щоб прочитати таблицю із вимірюваннями:
import numpy as npimport pandas as pddf = pd.read_csv("/kaggle/input/kyiv-air-quality-ai-lab-1/saveecobot_16788 2.csv")

Візьмемо лише стовпчик pm25 та побудуємо його графік, щоб краще зрозуміти наші дані:
pm25_data = df[df["phenomenon"] == "pm25"]pm25_data = pm25_data.reset_index()pm25_data["value"].plot()
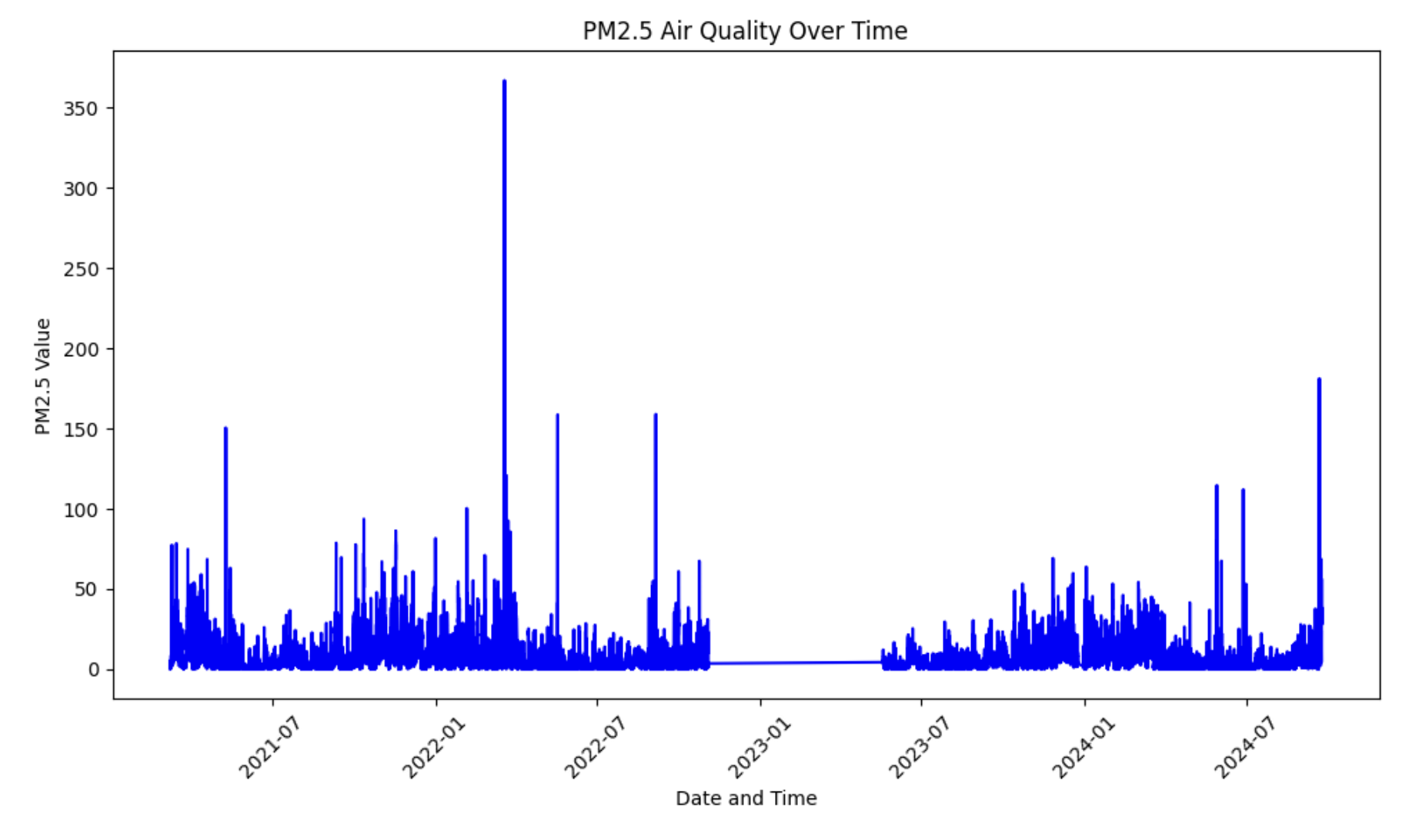
Тепер підготуємо дані для тренування прогнозної моделі. Для цього, спочатку треба розібратись що таке регресія.
| Регресія - це спосіб навчити комп’ютер передбачати числа. Наприклад, якщо ми знаємо, яка температура була вчора і позавчора, регресія допоможе передбачити, яка температура буде завтра. Вона шукає закономірність у даних і будує формулу, яка пов’язує одне з іншим. |
|---|
Більш формально, регресія - метод у машинному навчанні та статистиці, який використовується для виявлення залежності між змінними та прогнозування числового значення на основі цих залежностей.
Лінійна регресія — це найпростіший вид регресії, який шукає пряму лінію, що найкраще описує залежність між двома величинами.

Наприклад, для прогнозування температури повітря у найпростішому випадку змінна X може представляти температуру "сьогодні", а Y — температуру "завтра". Однак для більш якісного прогнозу зазвичай потрібно враховувати додаткові дані, такі як температура за "вчора", "позавчора", а також сезон чи місяць, у якому відбувається прогнозування. Ці додаткові фактори допомагають моделі краще зрозуміти закономірності та зробити точніше передбачення. Відповідно, змінна X насправді може бути не числом, а вектором, кожне число якого містить температуру за сьогодні та вчора, а також додаткові фактори як місяць та сезон. Наприклад: (-5, -4, 12, 4) може означати температуру -5 та -4 за два дні, 12 місяць (грудень), 4 сезон (зима).
Повернемось до якості повітря. Y у нас це якість повітря на завтра, а даними (X) будуть:
- якість повітря pm25 за вчора
- сьогоднішня дата
- номер місяця
- день тижня
from datetime import timedeltapm25_data['time_numeric'] = pm25_data['logged_at'].map(pd.Timestamp.toordinal)pm25_data['month'] = pm25_data['logged_at'].dt.monthpm25_data['weekday'] = pm25_data['logged_at'].dt.weekdaypm25_data['one_day_back'] = pm25_data['value'].shift(1)pm25_data.dropna(subset=['one_day_back'], inplace=True)# Define features and targetX = pm25_data[['month', 'one_day_back']]y = pm25_data['value']from sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)model = LinearRegression()model.fit(X_train, y_train)
Виконаємо кілька приготувань для того щоб зробити прогноз на наступні кілька днів. Створимо таблицю (DataFrame) future_data, яка буде містити X для всіх наступних 90 днів: дата, місяць, день тижня.
last_date = pm25_data['logged_at'].max()future_dates = [last_date + timedelta(days=i) for i in range(1, 90)]future_data = pd.DataFrame({ 'month': [date.month for date in future_dates], 'weekday': [date.weekday() for date in future_dates], 'one_day_back': np.nan})
last_pm25_value = pm25_data['value'].iloc[-1]for i in range(len(future_data)): future_data.loc[i, 'one_day_back'] = last_pm25_value last_pm25_value = model.predict(future_data.iloc[[i]][['month', 'one_day_back']])[0]predictions = future_data['one_day_back'].values
І намалюємо графік історичних даних та отриманих прогнозів одночасно:
plt.plot(pm25_data['logged_at'], pm25_data['value'], label='Historical PM2.5', marker='o')
plt.plot(future_dates, predictions, label='Predicted PM2.5', linestyle='--', color='red')
plt.show()
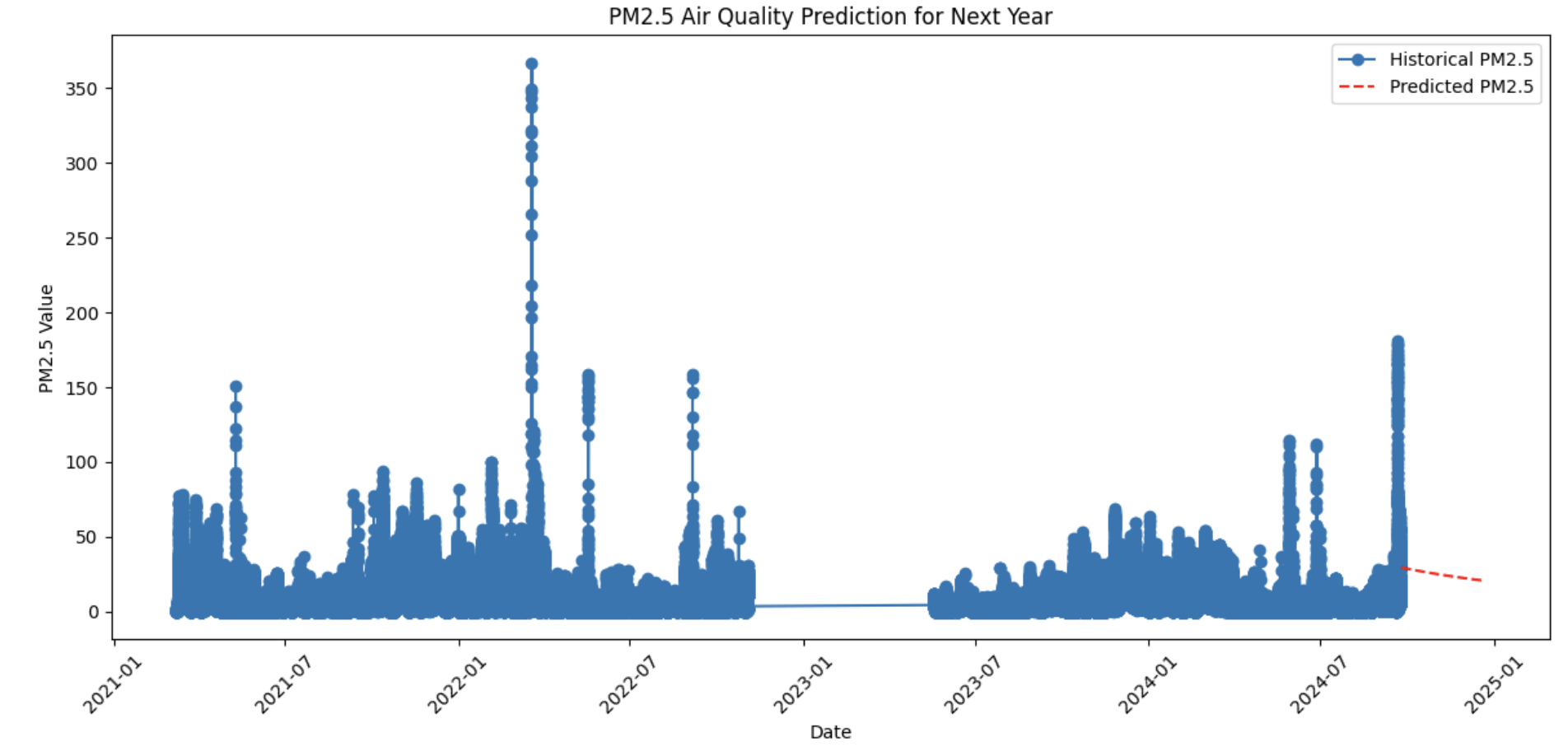
Прогнозовані дані демонструють більш стабільну функцію, ніж історичні дані і вказують на поступове зниження протягом наступних 90 днів. Додавання нових ознак (у вектор X) та зміна моделі можуть покращити результати прогнозування.